搜索到
101
篇与
的结果
-
 在用户的浏览器里挖矿——Anubis 网站防护工具配置教程 一、项目背景Anubis工作模式类似于Cloudflare的Javascript挑战,拦截请求之后,用户需要通过挑战之后才能继续访问。而Anubis需要客户端完成一定难度的Hash计算,简单说就是挖矿。客户端需要进行一定负载的计算,计算出正确结果之后才能进入网站。这对于正常用户的客户端来说并不算是什么,在难度2-4下,大概率计算时间小于2秒钟,一闪而过用户感知小。在难度5-6时,浏览器需要进行10-30秒以上的计算。在CC攻击的时候,攻击者会控制大量的无头浏览器进行攻击,使用Anubis之后,会在攻击者的无头浏览器中执行Hash计算,高难度的Hash计算会拖垮攻击者的服务器,从而降低攻击频率。项目官网我在本地Debian12 + NGINX系统中已经跑通,随后我会发表一篇博客详细描述配置PS;Anubis有非常强大的功能,包括针对不用GEOIP、不同AS的规则,正在进一步探索中。PPS;试了下难度设置为6,大概1分钟才计算完成,期间CPU(i5-13490H)占用80%左右。二、工作原理1 AnubisAnubis是一个网站防护工具,其工作原理类似常见的Cloudflare验证,会在用户进入网站之前对客户端进行检查。客户端需要完成一定难度的Hash计算,服务器验证计算结果后放行,Hash计算代表了客户端可能需要执行几千几万次的计算,而服务器验证执行执行一次,对服务器开销小。当有网络爬虫、CC攻击想进入源站是,需要在攻击者的客户端(比如无头浏览器中)进行一定量的Hash计算,攻击者一般会在一台物理机中运行多个配置了代理的无头浏览器,这些Hash计算会拖垮攻击者的服务器,从而迫使攻击者放弃或减低攻击频率。现代设备通常都具有一定的限制算力,这些任务对于这些客户端来说,通常只需要几毫秒或几秒中即可完成,用户只需要等待一段时间,不需要进行任何操作,成功后会自动进入实际后端服务。2.工作原理Hash计算和经典的比特币挖矿一致,客户端需要使用一个确定的字符串加上任意数字,进行 sha256 计算,得到的 64 为hash值的前x个数为 0,x就是difficultyconst hash = await sha256(`${challenge}${nonce}`);整体流程客户端第一次访问时,会根据访问者的IP、ASN、User-Agent,服务器的工作负载,计算出一个数值 weight,之后通过 weight 匹配不同难度的Hash计算任务给客户端。客户端完成计算后,由服务器进行验证,成功之后放行到真正的后端服务,同时返回 Set-Cookies 以保存一段时间验证结果,当用户下次访问时,可复用上次的验证结果。3.与NGINX搭配![[Pasted image 20250821210211.png]]流量从 80/443 端口进入之后,先交给Anubis进行拦截,延迟完成之后在交还回NGINX进行后续流程。在单个服务器内通过unix socks进行交互。三、安装/配置教程此处以Debian 12 系统为例1 安装Anubis1)下载并安装(1)请在Github获取最新的版本号wget -O /tmp/anubis.deb https://github.com/TecharoHQ/anubis/releases/download/v1.21.3/anubis_1.21.3_amd64.deb && apt install /tmp/anubis.deb(2)不能直连Github,可以使用加速域名,或者手动下载上传到服务器wget -O /tmp/anubis.deb https://ghfast.top/https://github.com/TecharoHQ/anubis/releases/download/v1.21.3/anubis_1.21.3_amd64.deb && apt install /tmp/anubis.deb(3)修改 /etc/anubis/default.env,内容如下BIND=/run/anubis/instance.sock BIND_NETWORK=unix SOCKET_MODE=0666 TARGET=unix:///run/nginx/nginx.sock(4)复制默认策略文件,暂不修改cp /usr/share/doc/anubis/botPolicies.yaml /etc/anubis/botPolicies.yaml2)systemd运行(1)创建service文件vi /etc/systemd/system/anubis.service[Unit] Description=Anubis Bot Protection After=network.target [Service] EnvironmentFile=/etc/anubis/default.env ExecStart=/usr/bin/anubis \ -bind /run/anubis/instance.sock \ -bind-network unix \ -socket-mode 0666 \ -target unix:///run/nginx/nginx.sock \ -metrics-bind 127.0.0.1:9091 \ -metrics-bind-network tcp \ -policy-fname /etc/anubis/botPolicies.yaml Restart=always User=www-data Group=www-data [Install] WantedBy=multi-user.target(2)创建目录mkdir -p /run/anubis /run/nginx(3)修改权限此处的用户和NGINX相同chown www-data:www-data /run/anubis /run/nginx(4)启用Anubissystemctl enable --now anubis.service(5)确保已经成功运行systemctl status anubis2 配置NGINX此处提供一份可用NGINX,请自行修改扩展user root; worker_processes auto; pid /run/nginx.pid; events { worker_connections 1024; } http { upstream anubis { server unix:/run/anubis/instance.sock; } server { listen 443 ssl http2; server_name uptime.vio.vin; ssl_certificate /etc/ssl/violet/certs/all.vio.vin.cert.pem; ssl_certificate_key /etc/ssl/violet/certs/all.vio.vin.key.pem; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_pass http://anubis; } } server { listen unix:/run/nginx/nginx.sock; server_name uptime.vio.vin; location / { proxy_pass http://10.115.15.178:3001; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } } }upstream:定义上游服务器为anubis第一个server:监听 443 入站连接,传输给anubis,传输客户端IP用于IP相关策略判断第二个server:anubis验证通过之后,实际反向代理的位置至此,基础配置已完成,默认情况下低分析客户端难度为 2,高风险为 43 Bot策略官网文档:https://anubis.techaro.lol/docs/admin/policies需要调整 botPolicies.yaml 文件默认的botPolicies.yaml 配置文件:https://github.com/TecharoHQ/anubis/blob/main/data/botPolicies.yamlbots中定义了多个规则,可以看到已经通过import导入了一部分规则,这部分的文件可以在 /usr/share/doc/anubis/data/bots 中找到默认的规则如下,可以仿照这些规则写自己的规则1)可配置匹配规则(1)匹配请求头/usr/share/doc/anubis/data/bots/cloudflare-workers.yaml- name: cloudflare-workers headers_regex: CF-Worker: .* action: WEIGH weight: adjust: 15(2)匹配User-Agent/usr/share/doc/anubis/data/bots/headless-browsers.yaml- name: lightpanda user_agent_regex: ^LightPanda/.*$ action: DENY - name: headless-chrome user_agent_regex: HeadlessChrome action: DENY - name: headless-chromium user_agent_regex: HeadlessChromium action: DENY(3)指定表达式/usr/share/doc/anubis/data/bots/aggressive-brazilian-scrapers.yaml- name: deny-aggressive-brazilian-scrapers action: WEIGH weight: adjust: 20 expression: any: # Internet Explorer should be out of support - userAgent.contains("MSIE") # Trident is the Internet Explorer browser engine - userAgent.contains("Trident") # Opera is a fork of chrome now - userAgent.contains("Presto") # Windows CE is discontinued - userAgent.contains("Windows CE") # Windows 95 is discontinued - userAgent.contains("Windows 95") # Windows 98 is discontinued - userAgent.contains("Windows 98") # Windows 9.x is discontinued - userAgent.contains("Win 9x") # Amazon does not have an Alexa Toolbar. - userAgent.contains("Alexa Toolbar") # This is not released, even Windows 11 calls itself Windows 10 - userAgent.contains("Windows NT 11.0") # iPods are not in common use - userAgent.contains("iPod")(4)匹配客户端IP/usr/share/doc/anubis/data/clients/mistral-mistralai-user.yaml# Acts on behalf of user requests # https://docs.mistral.ai/robots/ - name: mistral-mistralai-user user_agent_regex: MistralAI-User/.+; \+https\://docs\.mistral\.ai/robots action: ALLOW # https://mistral.ai/mistralai-user-ips.json remote_addresses: [ "20.240.160.161/32", "20.240.160.1/32", ](5)匹配GEOIP- name: countries-with-aggressive-scrapers action: WEIGH geoip: countries: - BR - CN weight: adjust: 10(6)匹配ASN- name: aggressive-asns-without-functional-abuse-contact action: WEIGH asns: match: - 13335 # Cloudflare - 136907 # Huawei Cloud - 45102 # Alibaba Cloud weight: adjust: 10(7)匹配后动作动作 解释ALLOW 允许,跳过后续所有检查DENY 拒绝访问CHALLENGE 进行客户端挑战WEIGH 修改请求权重ALLOW和DENY不再解释2)CHALLENGE- name: generic-bot-catchall user_agent_regex: (?i:bot|crawler) action: CHALLENGE challenge: difficulty: 16 # impossible report_as: 4 # lie to the operator algorithm: slow # intentionally waste CPU cycles and timename:名称,可自定义user_agent_regex:正则表达式匹配User-Agentaction:动作,立即进行客户端挑战challenge:客户端挑战配置difficulty:难度,16 表示计算出的hash值前 16 位为 0,不可能完成(比特币的前导 0 个数为 19-20),在客户端完成 16 为的计算可能需要几万年甚至更久(攻击者看者 99%的CPU陷入沉思)report_as:用户在界面上看到的难度数值(你甚至可以骗他,这个进度条怎么一直卡在 99%不走呢)algorithm:采用的Hash算法,slow故意折磨CPU3)WEIGH调整请求的权重,正数为增加权重,负数为减少权重,后续会进入到 thresholds 中,针对不同的请求设置不同的CHALLENGE0-10 的权重,进行快速算法,几乎不需要等待- name: mild-suspicion expression: all: - weight > 0 - weight < 10 action: CHALLENGE challenge: algorithm: metarefresh difficulty: 2 report_as: 24)其他根据服务器负载动态调整示例在配置文件中已给出,有需要可以启用 # ## System load based checks. # # If the system is under high load, add weight. # - name: high-load-average # action: WEIGH # expression: load_1m >= 10.0 # make sure to end the load comparison in a .0 # weight: # adjust: 20 ## If your backend service is running on the same operating system as Anubis, ## you can uncomment this rule to make the challenge easier when the system is ## under low load. ## ## If it is not, remove weight. # - name: low-load-average # action: WEIGH # expression: load_15m <= 4.0 # make sure to end the load comparison in a .0 # weight: # adjust: -10
在用户的浏览器里挖矿——Anubis 网站防护工具配置教程 一、项目背景Anubis工作模式类似于Cloudflare的Javascript挑战,拦截请求之后,用户需要通过挑战之后才能继续访问。而Anubis需要客户端完成一定难度的Hash计算,简单说就是挖矿。客户端需要进行一定负载的计算,计算出正确结果之后才能进入网站。这对于正常用户的客户端来说并不算是什么,在难度2-4下,大概率计算时间小于2秒钟,一闪而过用户感知小。在难度5-6时,浏览器需要进行10-30秒以上的计算。在CC攻击的时候,攻击者会控制大量的无头浏览器进行攻击,使用Anubis之后,会在攻击者的无头浏览器中执行Hash计算,高难度的Hash计算会拖垮攻击者的服务器,从而降低攻击频率。项目官网我在本地Debian12 + NGINX系统中已经跑通,随后我会发表一篇博客详细描述配置PS;Anubis有非常强大的功能,包括针对不用GEOIP、不同AS的规则,正在进一步探索中。PPS;试了下难度设置为6,大概1分钟才计算完成,期间CPU(i5-13490H)占用80%左右。二、工作原理1 AnubisAnubis是一个网站防护工具,其工作原理类似常见的Cloudflare验证,会在用户进入网站之前对客户端进行检查。客户端需要完成一定难度的Hash计算,服务器验证计算结果后放行,Hash计算代表了客户端可能需要执行几千几万次的计算,而服务器验证执行执行一次,对服务器开销小。当有网络爬虫、CC攻击想进入源站是,需要在攻击者的客户端(比如无头浏览器中)进行一定量的Hash计算,攻击者一般会在一台物理机中运行多个配置了代理的无头浏览器,这些Hash计算会拖垮攻击者的服务器,从而迫使攻击者放弃或减低攻击频率。现代设备通常都具有一定的限制算力,这些任务对于这些客户端来说,通常只需要几毫秒或几秒中即可完成,用户只需要等待一段时间,不需要进行任何操作,成功后会自动进入实际后端服务。2.工作原理Hash计算和经典的比特币挖矿一致,客户端需要使用一个确定的字符串加上任意数字,进行 sha256 计算,得到的 64 为hash值的前x个数为 0,x就是difficultyconst hash = await sha256(`${challenge}${nonce}`);整体流程客户端第一次访问时,会根据访问者的IP、ASN、User-Agent,服务器的工作负载,计算出一个数值 weight,之后通过 weight 匹配不同难度的Hash计算任务给客户端。客户端完成计算后,由服务器进行验证,成功之后放行到真正的后端服务,同时返回 Set-Cookies 以保存一段时间验证结果,当用户下次访问时,可复用上次的验证结果。3.与NGINX搭配![[Pasted image 20250821210211.png]]流量从 80/443 端口进入之后,先交给Anubis进行拦截,延迟完成之后在交还回NGINX进行后续流程。在单个服务器内通过unix socks进行交互。三、安装/配置教程此处以Debian 12 系统为例1 安装Anubis1)下载并安装(1)请在Github获取最新的版本号wget -O /tmp/anubis.deb https://github.com/TecharoHQ/anubis/releases/download/v1.21.3/anubis_1.21.3_amd64.deb && apt install /tmp/anubis.deb(2)不能直连Github,可以使用加速域名,或者手动下载上传到服务器wget -O /tmp/anubis.deb https://ghfast.top/https://github.com/TecharoHQ/anubis/releases/download/v1.21.3/anubis_1.21.3_amd64.deb && apt install /tmp/anubis.deb(3)修改 /etc/anubis/default.env,内容如下BIND=/run/anubis/instance.sock BIND_NETWORK=unix SOCKET_MODE=0666 TARGET=unix:///run/nginx/nginx.sock(4)复制默认策略文件,暂不修改cp /usr/share/doc/anubis/botPolicies.yaml /etc/anubis/botPolicies.yaml2)systemd运行(1)创建service文件vi /etc/systemd/system/anubis.service[Unit] Description=Anubis Bot Protection After=network.target [Service] EnvironmentFile=/etc/anubis/default.env ExecStart=/usr/bin/anubis \ -bind /run/anubis/instance.sock \ -bind-network unix \ -socket-mode 0666 \ -target unix:///run/nginx/nginx.sock \ -metrics-bind 127.0.0.1:9091 \ -metrics-bind-network tcp \ -policy-fname /etc/anubis/botPolicies.yaml Restart=always User=www-data Group=www-data [Install] WantedBy=multi-user.target(2)创建目录mkdir -p /run/anubis /run/nginx(3)修改权限此处的用户和NGINX相同chown www-data:www-data /run/anubis /run/nginx(4)启用Anubissystemctl enable --now anubis.service(5)确保已经成功运行systemctl status anubis2 配置NGINX此处提供一份可用NGINX,请自行修改扩展user root; worker_processes auto; pid /run/nginx.pid; events { worker_connections 1024; } http { upstream anubis { server unix:/run/anubis/instance.sock; } server { listen 443 ssl http2; server_name uptime.vio.vin; ssl_certificate /etc/ssl/violet/certs/all.vio.vin.cert.pem; ssl_certificate_key /etc/ssl/violet/certs/all.vio.vin.key.pem; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_pass http://anubis; } } server { listen unix:/run/nginx/nginx.sock; server_name uptime.vio.vin; location / { proxy_pass http://10.115.15.178:3001; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } } }upstream:定义上游服务器为anubis第一个server:监听 443 入站连接,传输给anubis,传输客户端IP用于IP相关策略判断第二个server:anubis验证通过之后,实际反向代理的位置至此,基础配置已完成,默认情况下低分析客户端难度为 2,高风险为 43 Bot策略官网文档:https://anubis.techaro.lol/docs/admin/policies需要调整 botPolicies.yaml 文件默认的botPolicies.yaml 配置文件:https://github.com/TecharoHQ/anubis/blob/main/data/botPolicies.yamlbots中定义了多个规则,可以看到已经通过import导入了一部分规则,这部分的文件可以在 /usr/share/doc/anubis/data/bots 中找到默认的规则如下,可以仿照这些规则写自己的规则1)可配置匹配规则(1)匹配请求头/usr/share/doc/anubis/data/bots/cloudflare-workers.yaml- name: cloudflare-workers headers_regex: CF-Worker: .* action: WEIGH weight: adjust: 15(2)匹配User-Agent/usr/share/doc/anubis/data/bots/headless-browsers.yaml- name: lightpanda user_agent_regex: ^LightPanda/.*$ action: DENY - name: headless-chrome user_agent_regex: HeadlessChrome action: DENY - name: headless-chromium user_agent_regex: HeadlessChromium action: DENY(3)指定表达式/usr/share/doc/anubis/data/bots/aggressive-brazilian-scrapers.yaml- name: deny-aggressive-brazilian-scrapers action: WEIGH weight: adjust: 20 expression: any: # Internet Explorer should be out of support - userAgent.contains("MSIE") # Trident is the Internet Explorer browser engine - userAgent.contains("Trident") # Opera is a fork of chrome now - userAgent.contains("Presto") # Windows CE is discontinued - userAgent.contains("Windows CE") # Windows 95 is discontinued - userAgent.contains("Windows 95") # Windows 98 is discontinued - userAgent.contains("Windows 98") # Windows 9.x is discontinued - userAgent.contains("Win 9x") # Amazon does not have an Alexa Toolbar. - userAgent.contains("Alexa Toolbar") # This is not released, even Windows 11 calls itself Windows 10 - userAgent.contains("Windows NT 11.0") # iPods are not in common use - userAgent.contains("iPod")(4)匹配客户端IP/usr/share/doc/anubis/data/clients/mistral-mistralai-user.yaml# Acts on behalf of user requests # https://docs.mistral.ai/robots/ - name: mistral-mistralai-user user_agent_regex: MistralAI-User/.+; \+https\://docs\.mistral\.ai/robots action: ALLOW # https://mistral.ai/mistralai-user-ips.json remote_addresses: [ "20.240.160.161/32", "20.240.160.1/32", ](5)匹配GEOIP- name: countries-with-aggressive-scrapers action: WEIGH geoip: countries: - BR - CN weight: adjust: 10(6)匹配ASN- name: aggressive-asns-without-functional-abuse-contact action: WEIGH asns: match: - 13335 # Cloudflare - 136907 # Huawei Cloud - 45102 # Alibaba Cloud weight: adjust: 10(7)匹配后动作动作 解释ALLOW 允许,跳过后续所有检查DENY 拒绝访问CHALLENGE 进行客户端挑战WEIGH 修改请求权重ALLOW和DENY不再解释2)CHALLENGE- name: generic-bot-catchall user_agent_regex: (?i:bot|crawler) action: CHALLENGE challenge: difficulty: 16 # impossible report_as: 4 # lie to the operator algorithm: slow # intentionally waste CPU cycles and timename:名称,可自定义user_agent_regex:正则表达式匹配User-Agentaction:动作,立即进行客户端挑战challenge:客户端挑战配置difficulty:难度,16 表示计算出的hash值前 16 位为 0,不可能完成(比特币的前导 0 个数为 19-20),在客户端完成 16 为的计算可能需要几万年甚至更久(攻击者看者 99%的CPU陷入沉思)report_as:用户在界面上看到的难度数值(你甚至可以骗他,这个进度条怎么一直卡在 99%不走呢)algorithm:采用的Hash算法,slow故意折磨CPU3)WEIGH调整请求的权重,正数为增加权重,负数为减少权重,后续会进入到 thresholds 中,针对不同的请求设置不同的CHALLENGE0-10 的权重,进行快速算法,几乎不需要等待- name: mild-suspicion expression: all: - weight > 0 - weight < 10 action: CHALLENGE challenge: algorithm: metarefresh difficulty: 2 report_as: 24)其他根据服务器负载动态调整示例在配置文件中已给出,有需要可以启用 # ## System load based checks. # # If the system is under high load, add weight. # - name: high-load-average # action: WEIGH # expression: load_1m >= 10.0 # make sure to end the load comparison in a .0 # weight: # adjust: 20 ## If your backend service is running on the same operating system as Anubis, ## you can uncomment this rule to make the challenge easier when the system is ## under low load. ## ## If it is not, remove weight. # - name: low-load-average # action: WEIGH # expression: load_15m <= 4.0 # make sure to end the load comparison in a .0 # weight: # adjust: -10 -
适合"养老"的网站收藏夹导航——基于Astro的导航站主题,支持 Vercel 和 Cloudflare Pages一键部署 1 前言源码来源于Nodeseek的zywe,源码地址。演示地址:dh.zywe.de关于xwnav-theme源码的简介:人人都能搭建的简洁美观收藏夹网站。不仅仅是简单的链接集合,更是智能化的导航平台,让您只需专注于内容管理而非技术细节,**只需编辑一个数据文件,所有功能都会自动更新,极大简化了维护工作,打包后部署超轻量化(1-2mb)。🌟 独特优势🤖 自动化功能,让您只需专注于内容管理而非技术细节,只需修改一个数据文件(src/data/navLinks.js),所有功能都会自动更新,极大简化了维护工作自动化功能🖼️ 自动图标获取:添加新网站和新分类时无需手动下载图标,脚本自动获取并优化图标引用图标一条龙📑 自动分类导航:侧边栏分类导航会根据数据文件自动更新,无需手动修改HTML🔎 自动搜索索引:搜索功能会自动检测新增网站和分类,无需额外配置🃏 自动卡片生成:网站卡片布局会自动适应新增内容,保持一致的视觉效果🎨 自动主题切换:根据用户系统配置自动切换暗色/亮色主题🧹 自动清理图标:图标管理脚本会自动清理未使用的图标文件,保持项目整洁📱 自动响应式适配:无需编写额外代码,完美适配各种设备屏幕🗺️ 自动生成站点地图:每次构建项目自动生成robots.txt和sitemap.xml📝 自动SEO元数据:每次构建项目自动生成和管理SEO相关的元标签等等代码🟢灯塔PageSpeed Insights2🌈 主要特点🏷 简洁直观的界面:分类清晰,操作便捷🔍 智能搜索功能:快速查找您需要的网站📎 双分类导航栏:主页横向导航+侧边导航📃 卡片式网站展示:直观美观,一目了然🔄 自动化工作流:减少手动操作,提高效率🌓 暗色模式:智能切换暗色/亮色模式⏱️ 快速返回顶部:一键回到顶部的便捷按钮🚀 快速加载:基于Astro框架构建,性能卓越📸 图片懒加载:提升加载速度和用户体验🔊 流畅的动画过渡:提升用户界面交互体验💻 智能顶部栏: 上滑展出,下滑收缩不挡视野🙌 人性化设计: 搜索框侧边栏可点空白处退出🌤️ 实时天气显示:集成API实时获取当地天气📱 响应式布局:适配所有设备屏幕🔒 无需数据库:纯静态设计,无需数据库🔑 隐藏链接地址:悬停在卡片,不显示链接地址💾 Island岛屿架构按需加载:动态组件独立渲染,提升加载速度静态首屏:首屏纯静态生成,并行加载交互组件延迟水合:交互元素延迟水合,减少首屏阻塞查询优先:搜索和导航操作优先渲染浏览器缓存:利用存储机制优化重复访问3🎶 部署教程推荐:本地Windows开发 + Linux服务器部署:本地开发和构建,仅将执行构建命令后的dist目录部署到服务器3.1 git 拉取git clone https://github.com/zywe03/astro-nav-theme.git(或者下载压缩包源码解压)3.2 windowns安装Node.js 环境安装 Node.js 18.0+ (推荐LTS版本)官网Windows用户:直接从官网下载安装包3.3 包管理器选择启用 pnpm(轻量、高效)corepack enable corepack prepare pnpm@latest --activate3.4 开始安装# 安装依赖 pnpm i # 浏览器实时看效果 pnpm dev # 自动下载图标 npx tsx .\icon-system\0icon.ts # 打包构建生成/dist目录 pnpm build3.5 上传/dist目录到服务器,nginx反代4 借助AI导入导航数据第一次导入大量网址链接,借助AI快速生成网站导航内容(强烈建议)列出想要生成的网站所属分类,名称或网站,短和长描述让AI生成,节省工作量AI提示词:统一分类opensource 网站: github baidu.com 谷歌 具体按照以下样式生成,使用“JavaScript风格格式+单引号”,不要添加"icon字段"和"[]"" { id: 'github', title: 'GitHub', description: '全球最大的开源代码托管平台,支持 Git 版本控制,适用于协作开发、项目管理和自动化工作流,是开发者共享与协作的核心工具。' shortDesc: '代码托管平台。', url: 'https://github.com/', category: 'opensource', }, 描述根据网站实际内容,专业,准确,介绍背景独特优势等等,不要太刻板,臃肿,重复插入数据文件navLinks.js后 执行npx tsx .\icon-system\0icon.ts自动下载图标,即可完成,大量导航网站导入5 💬 日常使用关键文件和目录说明5.1 核心数据文件src/data/navLinks.js: 存储所有网站数据和分类信息,是最常修改的文件,包含网站信息和分类定义5.2 图标存储public/icons/: 存储所有网站图标public/icons/category/: 存储分类图标public/icons/downloaded_sites/: 临时下载目录(自动清理)public/icons/downloaded_categories/: 临时下载目录(自动清理)5.3 📝 增删网站和分类修改 src/data/navLinks.js 文件即可管理所有网站和分类建议统一用一种格式JavaScript风格格式+单引号,避免脚本错误识别5.3.1 添加新分类在 categories 数组中添加新分类:⚠️ 注意:不要手动添加icon字段,不要icon""字段留空,都会导致图标无法自动下载添加icon字段,手动自定义图标除外export const categories = [ // 分类注释 { id: new, //分类ID name: '新分类名称',icon: '/icons/category/new-category.svg' // 分类图标也支持自动生成,基于name的首字生成 } ];5.3.2 添加新网站在 sites 数组中添加新网站:export const sites = [ { id: 'github', // 网站ID title: 'GitHub', // 网站名称 description: '全球最大代码托管平台。', // 网站描述 shortDesc: '代码托管平台。', // 简短描述 url: 'https://github.com/', // 网站链接(包含完整协议(`http://`或`https://`)) category: 'opensource', // 所属分类 ID(必须对应分类中的id) // 注意:不需要添加icon字段,脚本会自动处理 }, ];5.3.3 网站和分类排序一句话调顺序即可分类排序: 调整 categories 数组中分类的顺序即可改变分类的显示顺序网站排序: 调整 sites 数组中网站的顺序即可改变网站的显示顺序生成后插入navLinks.js即可5.4 🖼️ 图标下载脚本使用指南✅ navLinks.js使用“JavaScript风格格式+单引号”,不要添加"icon字段" 由于是静态网站,建议全部图标在构建时下载图标引用使用步骤:首先在 src/data/navLinks.js 中添加好新网站或分类一键执行:# 终端复制粘贴回车 npx tsx .\icon-system\0icon.ts5.5 🔗 修改友情链接和按钮✅使用vscode搜索文本记得修改可快速找到全部需要自定义的内容(强烈建议搜索)5.5.1 修改友情链接和页脚声明位于页脚组件中,修改 src/components/Footer.astro 文件:点开文件一目了然5.5.2 修改网站大标题(名称)和logo修改src\components\LogoName.astro独立出来方便修改,点开文件一目了然5.5.3 修改全部图标default.svg导航网站三级回退机制保底图标logo.png网站社交媒体分享图片logo.svg网站主图标准备您的图标文件(修改图片,但使用固定命名)替换图标文件放入 public\images 目录即可5.5.4 提交站点地图只需要向搜索引擎提交 https://xxx.com/sitemap-index.xml 这一个文件
-
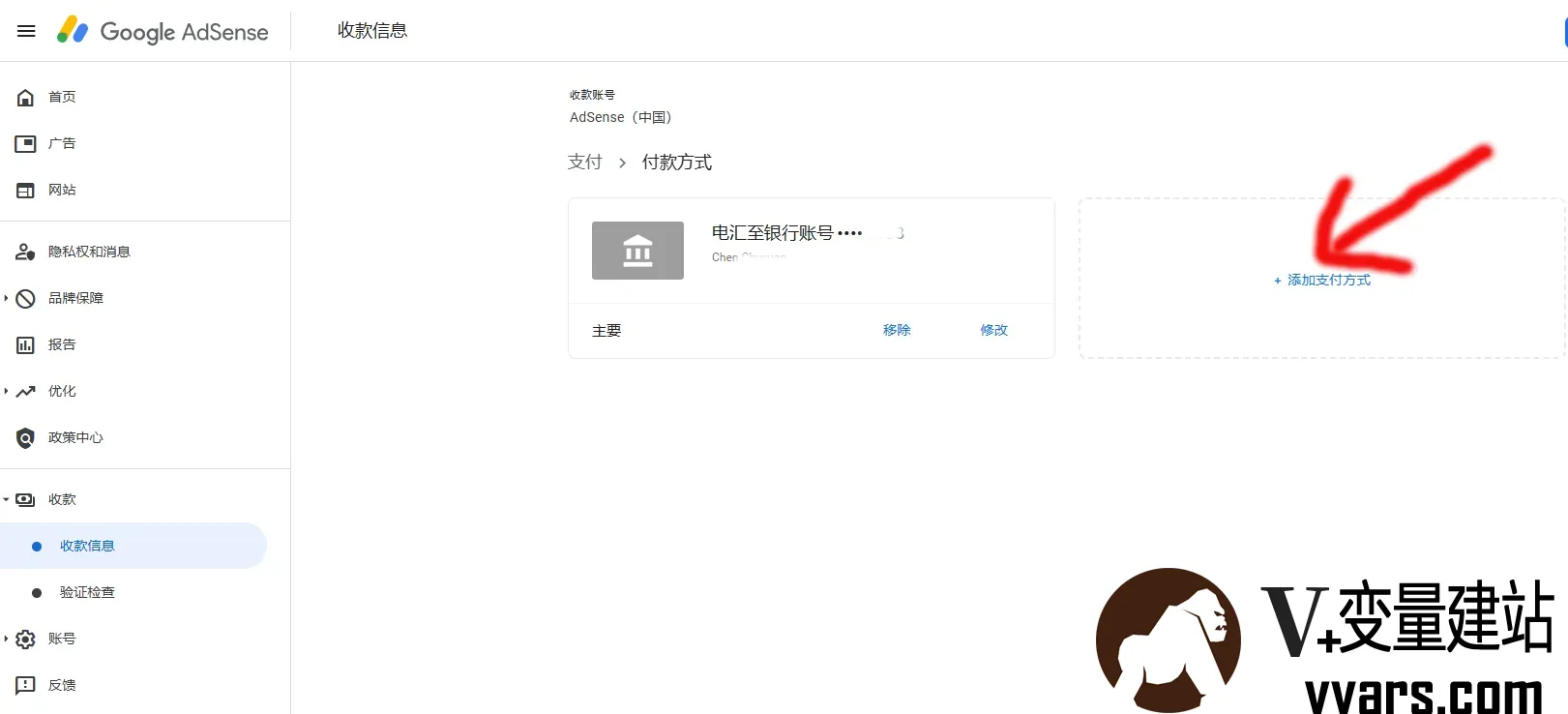
Google AdSense 国内提现教程:首选无手续费的招商银行 一.前言大家都知道,Google Adsense 在收益达到 100 美元后,便会自动使用电汇付款到绑定的银行卡。目前本站每天都有不到1美元的收益,日积月累,很快也到100美元的支付门槛了,但因为迟迟没有办理具有接受外汇的银行卡,导致推迟到现在才把这些流程搞定,而且收到了来自 Google Adsense 的首笔付款。今天就梳理一下我从办理银行卡到收到来自 Google Adsense 首笔打款的经历,同时也方便为自己做个记录,希望对大家有所帮助。二、adsense设置国内银行卡收款2.1 办理可以接收外汇的银行卡并非所有的银行卡均支持接受外汇,使用前请询问发卡地银行是否支持。关于手续费与合同的问题,我发现每个地方的政策都不一样。有些银行可能会存在手续费或是要求提供合同,有点麻烦。基于个人经验,本地的招商银行并未要求提供任何的合同也不存在任何的手续费用。这点,其实可以在询问银行卡能否接收外汇的时候一并问一下。 博主办理的是招行储蓄卡,因为免手续费,没有的小伙伴先申请一张招商银行一卡通。注意:银行卡必须为一类账户,二类及以下账户没有收款外币权限。开通网银和手机银行。招行的收款信息如下:收款行信息(招商银行总行) 银行名称(英文): China Merchants Bank 银行地址(英文):China Merchants Bank Tower NO.7088, Shennan Boulevard, Shenzhen, China 银行 SWIFT 代码: CMBCCNBS 收款人名称: 开户证件姓名的汉语拼音 收款人账号: 一卡通卡号2.2 填写 Adsense 付款方式登录 Google AdSense 管理后台点击 付款 > 付款信息 > 管理付款,添加付款方式。在付款页面可以根据下面信息来填写:付款人 ID(可选):不用填 银行账户上的姓名:Ma Baoguo(姓名拼音,大写,姓和名之间空格) 银行名称:China Merchants Bank(招行总行,不管哪个地方办理的卡都一样) SWIFT BIC:CMBCCNBS 账号:招商银行一卡通卡号 勾选设为主要付款方式 填写完成后,点击保存即可!2.3 等待AdSense 付款注意付款方式添加完成后并不会立刻就付款过来,需要等到余额达到 $100 后,谷歌 AdSense 固定在每个月 21 日(中国时间 22 日)发起付款,1-3 工作日可收到汇款。注意:一般来说 Google Adsense 款项在放款当天算起的 5 个工作日内会到达银行,银行再逐级向下放款,最终才会到达你的银行帐号。不要太着急,十来天到账也很正常。就像此次,我的收款正好赶上五一黄金周假期,假期肯定是没有办法到账,假期一过就到账了。三.招行 APP 结汇我们收到的汇款是美元,需要结汇成人民币,然后才能提现。下载安装登陆招商银行一卡通 APP,找到【外汇结汇】,点开后点击【去结汇】,在【结汇委托】界面:卖出货币:选择美元现汇 结汇资金来源:选择【其他经常转移】或【职工报酬和赡家款】 结汇金额:输入要结汇的金额 最后点击确定,输入密码即可成功结汇,结汇后的人民币就自动打入银行卡。另外需要注意每个人年度结汇总额度为 $50000,如果超出可到银行柜台申请额度。结汇业务办理时间是 8:30-22:00。到此为止,我们就可以通过 Google AdSense 赚取美元,然后结汇成人民币,最后提现到银行卡了。
-
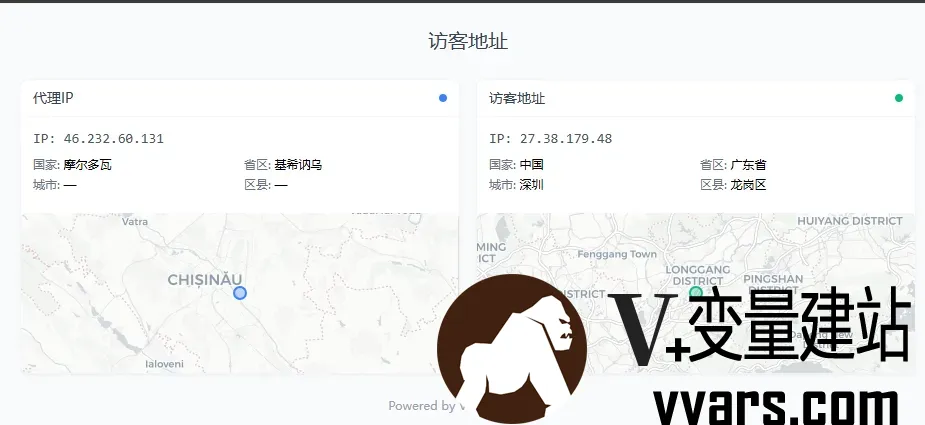
给自己网站增加一个定位插件——调用美团API定位到访者的IP地址 1 前言美团通过IP地址可以快速定位,利用美团API可以给网站增加一个定位到访者的插件。美团API地址为:https://apimobile.meituan.com/locate/v2/ip/loc?rgeo=true&ip=。本文介绍如何调用美团API定位到访者的IP地址,给自己网站增加一个定位插件。2 部署教程2.1 新建ip.php文件在网站目录下新建ip.php文件,如可以选择在子目录tools下新建ip.php文件,其代码如下:<?php if ($_SERVER['REQUEST_METHOD'] === 'POST' && isset($_POST['ip'])) { $ip = $_POST['ip']; $ipData = json_decode(file_get_contents("https://apimobile.meituan.com/locate/v2/ip/loc?rgeo=true&ip=" . urlencode($ip)), true); if (!$ipData || !isset($ipData['data']['lat'])) exit(json_encode(['success' => false])); $lat = $ipData['data']['lat']; $lng = $ipData['data']['lng']; $rgeo = $ipData['data']['rgeo']; $cityData = json_decode(file_get_contents("https://apimobile.meituan.com/group/v1/city/latlng/{$lat},{$lng}?tag=0"), true)['data'] ?? []; exit(json_encode(['success' => true, 'ip' => $ip, 'lat' => $lat, 'lng' => $lng, 'country' => $rgeo['country'] ?? '', 'province' => $rgeo['province'] ?? '', 'city' => $rgeo['city'] ?? '', 'district' => $rgeo['district'] ?? '', 'detail' => $cityData['detail'] ?? ''])); } ?> <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"><title>IP Locator</title><meta name="viewport" content="width=device-width,initial-scale=1"> <script src="https://cdn.tailwindcss.com"></script> <link href="https://fastly.jsdelivr.net/npm/[email protected]/dist/leaflet.min.css" rel="stylesheet"/> <script src="https://fastly.jsdelivr.net/npm/[email protected]/dist/leaflet.min.js"></script> </head> <body class="bg-slate-50 font-sans p-3 md:p-6"> <div class="max-w-4xl mx-auto"> <h1 class="text-xl font-medium mb-6 text-center text-gray-700">访客地址</h1> <div class="grid md:grid-cols-2 gap-4" id="cards"></div> <div class="text-center text-xs text-gray-400 mt-6">Powered by <a href="https://www.Vvars.com">V+变量建站日记</a></div> </div> <script> (async () => { const sources = [ {id: 'f', url: 'https://ipv4.lvhai.org/', label: '代理IP', color: '#3b82f6'}, {id: 'd', url: 'https://ipv4_cu.itdog.cn/', label: '访客地址', color: '#10b981'} ]; // Create cards & fetch IPs sources.forEach(s => { document.getElementById('cards').innerHTML += ` <div class="bg-white rounded-lg shadow-sm border border-gray-100 overflow-hidden"> <div class="px-3 py-2 border-b border-gray-100 flex items-center justify-between"> <h2 class="text-sm font-medium text-gray-700">${s.label}</h2> <div class="h-2 w-2 rounded-full" style="background:${s.color}"></div> </div> <div id="${s.id}-content" class="p-3 text-sm"> <div class="animate-pulse h-4 w-20 bg-gray-200 rounded"></div> </div> <div id="${s.id}-map" class="h-40 rounded-md mt-2 hidden"></div> </div>`; // Process IP (async () => { try { // Get IP const ip = await fetch(s.url).then(r => s.url.includes('lvhai') ? r.text().then(t => { try { return JSON.parse(t).ip || t.trim(); } catch { return t.trim(); } }) : r.json().then(j => j.ip)).catch(() => null); if (!ip) { document.getElementById(`${s.id}-content`).innerHTML = `<div class="text-red-500">Failed to get IP</div>`; return; } document.getElementById(`${s.id}-content`).innerHTML = `<div class="font-mono text-gray-600">IP: ${ip}</div>`; // Get location const data = await fetch(location.href, { method: 'POST', headers: {'Content-Type': 'application/x-www-form-urlencoded'}, body: `ip=${encodeURIComponent(ip)}` }).then(r => r.json()); if (!data.success) { document.getElementById(`${s.id}-content`).innerHTML += `<div class="text-red-500 text-xs mt-1">Location failed</div>`; return; } // Update content document.getElementById(`${s.id}-content`).innerHTML = ` <div class="font-mono text-gray-600">IP: ${ip}</div> <div class="grid grid-cols-2 gap-x-2 gap-y-1 text-xs mt-2"> <div><span class="text-gray-500">国家:</span> ${data.country||'—'}</div> <div><span class="text-gray-500">省区:</span> ${data.province||'—'}</div> <div><span class="text-gray-500">城市:</span> ${data.city||'—'}</div> <div><span class="text-gray-500">区县:</span> ${data.district||'—'}</div> </div>`; // Show map with CARTO basemap const mapEl = document.getElementById(`${s.id}-map`); mapEl.classList.remove('hidden'); const map = L.map(mapEl, {zoomControl: false, attributionControl: false}).setView([data.lat, data.lng], 10); L.tileLayer('https://{s}.basemaps.cartocdn.com/light_all/{z}/{x}/{y}{r}.png', { subdomains: 'abcd' }).addTo(map); L.circleMarker([data.lat, data.lng], {radius: 6, color: s.color, weight: 2, fillOpacity: 0.3}).addTo(map); setTimeout(() => map.invalidateSize(), 100); } catch (err) { document.getElementById(`${s.id}-content`).innerHTML = `<div class="text-red-500">Error: ${err.message}</div>`; } })(); }); })(); </script> </body> </html>2.2 在网站模板中加入调用代码可以采用iframe调用,示例代码如下:<iframe frameborder=0 src="https://www.vvars.com/tools/ip.php" style="border-radius:8px; height: 300px; transform: scale(0.85); transform-origin: top left;"></iframe>代码参考,需要自行调整height和scale数值。3 最终效果IP显示:https://www.vvars.com/tools/ip.php网站调用显示:https://www.vvars.com/Website-construction/Add-a-location-plug-in-to-your-website---call-Meituan-API-to-locate-the-visitor-s-IP-address.html
-
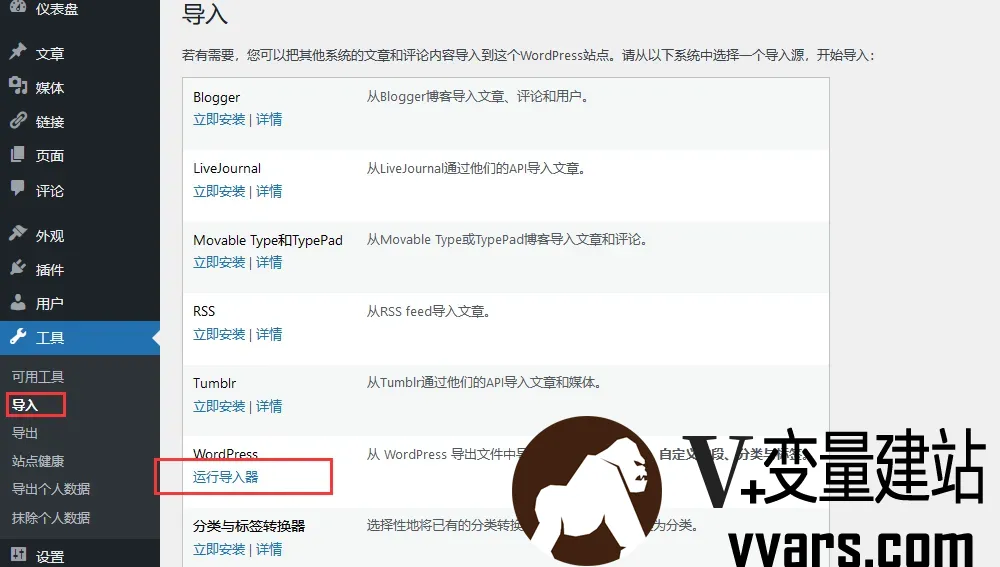
化繁为简,帝国cms博客数据迁移至wordpress详细教程 一 前言5Var美食谷(5var.com)是我很早就建立的一个美食网站,运行几年流量还是少的可怜,可能是来自搜索引擎的流量太少了,毕竟酒香也怕巷子深,本着死马当活马医的想法,索性就搬到wordpress,毕竟wordpress才适合博客……这里并不是说帝国不适合建站。二 转换教程以下迁移详细记录与代码。1 第一步:搭建wordpress官网下载wordpress即可,安装的时候正常安装即可。2 第二步:安装导入数据的工具可以安装wordpress导入器插件。3 第三步:导出帝国的数据这里导出数据就需要用到代码了,只导出文章和分类,分类url如果规则的话,可以保留不变,如果每个分类下都有不同的url形式的话,那就不行了。在你帝国网站根目录建立一个etow.php,然后将下面的代码放进去,访问这个PHP即可看到xml数据,这时候Ctrl+S保存,保存为xml文件。etow.php代码如下:隐藏内容,请前往内页查看详情4第四步:导入wordpress这样便可以把你帝国的数据转移到wordpress里面了。
-
关于本站V+变量最近的服务器转移和升级的说明 1 小站迁徙之路1)本站最早是在腾讯云清凉云广州,当时是2021三年活动入手的,但是没时间打理,基本属于放羊状态。2)2024年9月,因腾讯云到期,续费价格较高,又不想各种凑券退款之类的便宜入手,于是转移到德国Netcup 黑五活动的VPS1000的服务器,不得不说Netcup的性价比真的很高,5.75O就有4C -8G-512GSSD的配置,德国大厂真的超级稳定,直到现在本站的图床https://imgq.de还是建在Netcup。3)最近,碰到Yxvm和Nodeseek正在开展免费赞助活动,见NodeSupport免费服务器赞助计划,正好本站流量也达标了,抱着试一试的心态申请了下,结果几个小时后就获批了,真的很感谢Yxvm和Nodeseek!2 小站升级接着本次迁徙的机会,想着给小站也来个php和Mysql升级,主要就是Php7→8,Mysql5.6→MariaDB10。本站用的是Typecho程序,网上搜了下是支持PHP8和MariaDB10的,于是马上开搞。整体很顺利,这里记录下:1)Yxvm VPS安装lnmp(PHP8和MariaDB10)直接用军哥的lnmp一键脚本,刚好4.2号军哥发了lnmp2.2:wget https://soft.lnmp.com/lnmp/lnmp2.2.tar.gz -O lnmp2.2.tar.gz && tar zxf lnmp2.2.tar.gz && cd lnmp2.2 && ./install.sh lnmp注意,这里我碰到报错,压缩包有点问题,我是下载到本地解压后上传到VPS的,可以正常安装和使用。2)Netcup上导出数据库,数据库不大,直接phpmyadmin可视化操作;3)Yxvm VPS安装Verysync,将vvars.com网站文件从netcup同步过来;#(如果需要指定索引存放位置请在最后面添加-d 路径 如 -d /data/verysync) curl http://www.verysync.com/shell/verysync-linux-installer/go-installer.sh > go-installer.sh chmod +x go-installer.sh ./go-installer.sh4)Yxvm VPS上phpmyadmin导入从Netcup导出的数据库;实践证明MariaDB是可以兼容Mysql5.6的,直接导入成功,没有报错;5)修改config.inc.php数据库配置服务器地址、账号密码,确保能连接;6)本站用了cloudflare的优选,所以只需要切换源站IP即可;7)测试Vvras.com打开、登录和修改是否正常,一切正常。
-
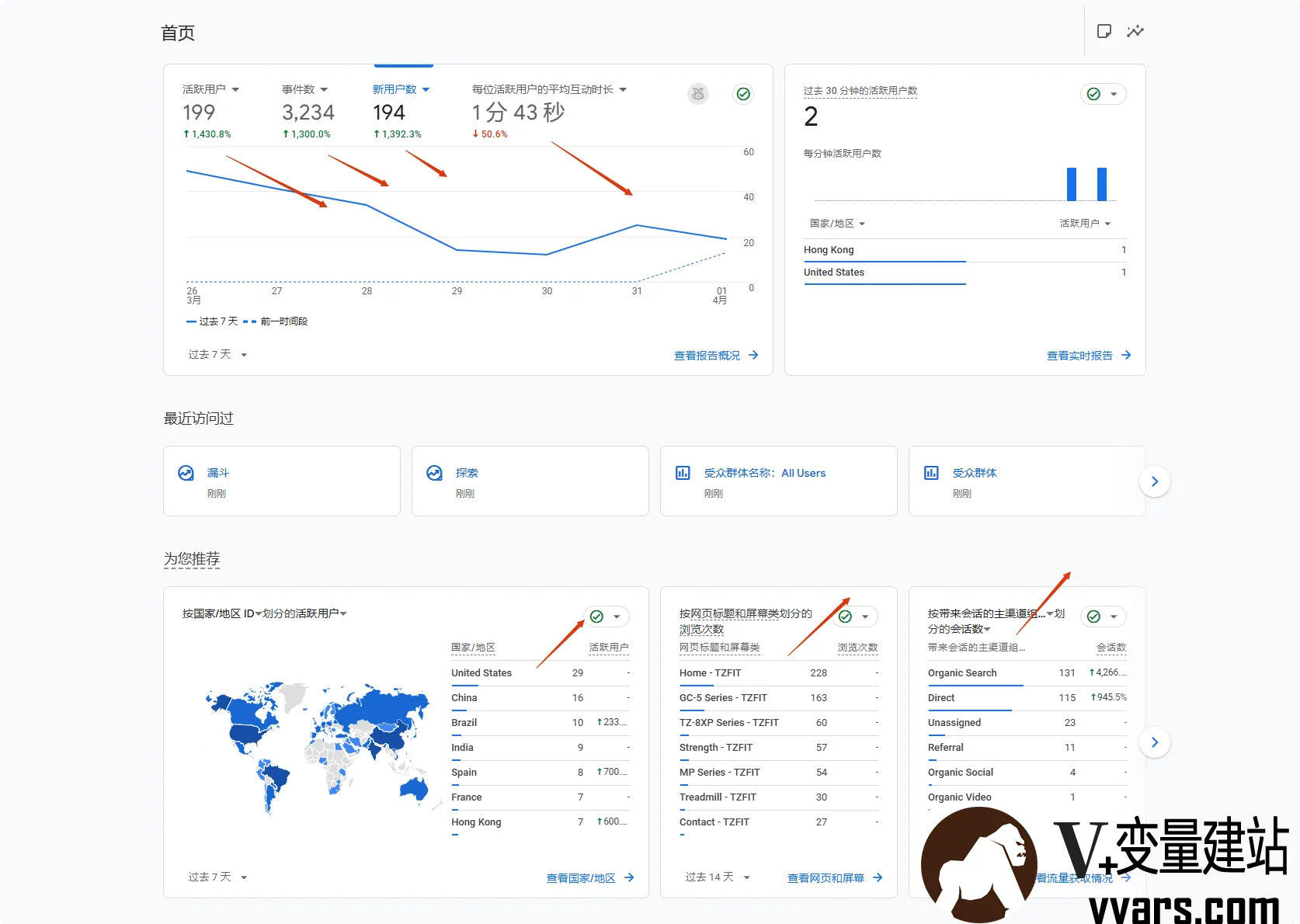
新手学SEO的利器——如何用Google Analytics查看数据优化SEO效果 一 前言谷歌分析(google analytics)是做seo非常重要的工具,那么如何用Google Analytics查看数据优化SEO效果呢。今天就来介绍下具体分析。二 主要SEO指标1 首页概况主要查看活跃用户,新用户数量和平均互动时长,也就是停留时间。越多,越长越好。下面是主要的国家和浏览的页面,以及自然流量,直接进入,unassigned是指没有路径流入的流量,再下面是推荐分享,社媒自然流量。2 下拉可以选择更多的数据,事件。3 报告概览也是差不多数据,主要除了关注流量来源的国家还要关注主要查看的页面来进行更加深度的优化,其他的页面也要优化,先后问题。4 实时流量情况当前30分钟或者5分钟的浏览用户数量,会话数量及浏览的页面。5 页面实时浏览情况也是一样,查看用户感兴趣的页面是哪一些。6 地区城市,和流量来源的搜索引擎其他重复的数据我就不一一介绍了,挑重点的讲。这一块潜在客户需要注意的点是地区城市,和流量来源的搜索引擎,可以进行更细化的广告投放。7 查看自然流量以及直接搜索来的流量占比。8 用户关注的页面是哪一些,针对性的优化,增加点击率转化率。9 2C数据就不看了,也是一样道理,主要做的还是B2B。10 应用流量概览,多语言这一块要注意,小语种的市场还是非常有潜力的。我们做广告的时候,最好是针对好的样本数据,针对国家地区去分组投放广告做测试。11 查看波动时间点以及情况,给我们谷歌广告投放的时间段参考。12事件主要几大类,pv用户查看的页面数量,user engagement停留时间或者用户活动时间总和,scoll 滑动,session start跟踪每次用户做了什么,算是小型的用户搜索旅途映射。First visit,判断用户是不是第一次进入,新用户的比例。video process,查看视频的数量,view search results,查看搜索结果的用户量。13语言的划分。14变量,不同形式不同国家来源的用户量归纳。15点击应用,会显示各个细分来源的比例。16用户路径的分布。17用户的搜索浏览路径以及具体来源IP的国家,地区。
-
Typecho全站启用HTTPS教程的坑 全站启用HTTPS让您的网站更安全,随着用户和搜索引擎的不断重视,很多小伙伴们已经加入HTTPS的阵营,分享下Typecho设置HTTPS的过程。1申请SSL证书如果您还没有域名SSL证书,可以参考教程:沃通免费SSL证书申请和Let’s Encrypt免费SSL证书申请免费的SSL证书。2 Typecho设置登录Typecho后台 -> 设置 -> 基本设置 -> 站点地址改成https的域名是必须的。3编辑Typecho站点根目录下的文件config.inc.php加入下面一行配置,否则网站后台还是会调用HTTP资源。/** 开启HTTPS */ define('__TYPECHO_SECURE__',true);4 评论替换由于Chrome浏览器对HTTPS要求较高,Firefox已经显示小绿锁,可是Chrome还是有警告提示,F12查看,评论表单的action地址还是HTTP,找到站点主题目录下的comments.php文件,并搜索$this->commentUrl(),将其替换为:echo str_replace("http","https",$this->commentUrl()); 最后保存。5 HTTP重定向到HTTPS但是这样HTTP的方式还是可以访问的,我们可以通过WEB服务器(Ningx)将80端口(HTTPS)重定向到443端口(HTTPS),强制全站HTTPS,请参考文档:Nginx强制https,HTTP 301重定向到HTTPS说明。6 查看效果最后清除浏览器缓存访问下自己的网站,浏览器已经显示安全的小绿锁标识,如果没有出现小绿锁,请通过浏览器F12分析是否还加载了不安全的HTTP资源。
-
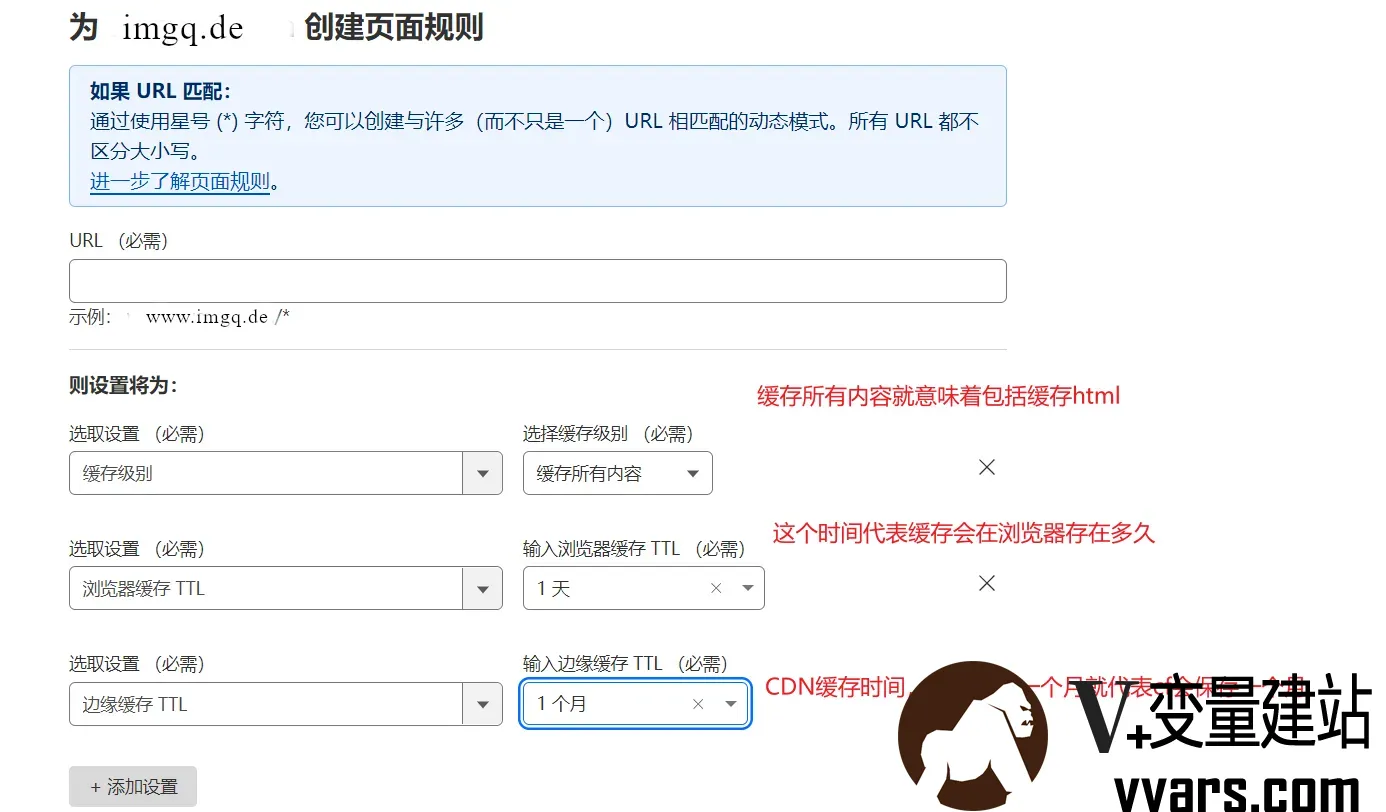
充分利用cloudflare的缓存功能来实现网站加速——Cloudflare进阶技巧:缓存利用最大化 一 前言cloudflare我想你应该知道是什么,一家真正意义上免费无限量的CDN,至今未曾有哥们喷它的。当然,在国内的速度确实比较一般,不过这也不能怪它。CDN最大的特色,我想就是它的缓存功能,达到防攻击,减轻源服务器的压力。着重聊一聊cloudflare的缓存功能,你还在使用默认的缓存配置?这篇文章可以给你带来对cloudflare缓存的进一步了解。关于cloudflare,本站之前有介绍过如何用cloudflare给tyepecho博客加速:利用cloudflare给你的typecho加速——Typecho博客系统专用的CloudFlare缓存规则二 cloudflare默认缓存配置2.1 特点1、仅对静态资源生效,比如js、css等等完整格式:.7z .csv .GIF .MIDI .PNG .TIF .ZIP .AVI .DOC .GZ .MKV .PPT .TIFF .ZST .AVIF .DOCX .ICO .MP3 .PPTX .TTF .APK .DMG .ISO .MP4 .PS .WEBM .BIN .EJS .JAR .OGG .RAR .WEBP .BMP .EOT .JPG .OTF .SVG .WOFF .BZ2 .EPS .JPEG .PDF .SVGZ .WOFF2 .CLASS .EXE .JS .PICT .SWF .XLS .CSS .FLAC .MID .PLS .TAR.XLSX HTML2、刷新时间,一般为2小时。2.2 不足如果我想缓存html页面呢,甚至说我想缓存MP4视频格式(在这里不推荐大面积缓存视频,如果你不想被封的话)生效时间只有2小时,让人不满足,我想生效时间长一点,怎么办?三. 配置缓存的方式3.1 页面规则如果只是配置缓存的话,我不推荐使用页面规则,因为免费账号的页面规则是有3条,而且它支持的功能更全面,很明显它是十分珍贵的,不应该浪费在简单的缓存上。不足之处:页面规则的缓存支持的最长时间也不过才一个月,可以看看第二种方式,支持时间会更久。3.2 Cache Rules看一下入口位置,缓存 → Cache Rules → 创建规则,值得一提的是,它支持10条规则,足够大部分人的需求。我们再看看规则的具体配置吧亮点:规则数目支持10条 默认缓存所有 最长时间竟然高达一年之久 对于这种优点,我们没有理由不心动。四. 应用场景图床:图片这种东西,我想是不需要修改的吧,缓存它没有任何坏处。 视频:不推荐!除非你是缓存几个小视频,不大面积使用,这种是没什么问题的。 目录程序:在这里提到Alist,我使用的是这个。你可能会好奇,为什么提到它,因为我们常用的存储有OneDrive、阿里云盘等等,但是,我们都知道它并不是无限制使用。如果在短时间有大量请求,是会报429的,那不就报废了吗?但是如果我们开启本地代理,然后对下载地址进行缓存,会发生什么?大大减轻了源下载的压力,从此和限频说拜拜。 值得注意的是,只推荐缓存小文件!因为缓存太多大文件,会大大提高被封禁的风险。 静态博客:反正已经是静态博客了,直接全站缓存。4.1 如何判断缓存是否生效?如果你发现显示Hit,就代表你成功了。五. 结语cloudflare是一把利剑,我只是展示了其中的一个方面,更多功能需要你来开发。剑是死的,人是活的,发挥你的主观能动性吧。
-
利用cloudflare给你的typecho加速——Typecho博客系统专用的CloudFlare缓存规则 一 前言好久都没有更新Typecho博客了,最近几天V+变量测试了一套适用于Typecho博客系统的CloudFlare缓存规则,经过近一周时间的测试确定有效,并且加速效果特别突出,今天就无偿分享给大家,也算是为国内Typecho生态添砖加瓦了吧!总结下来,这套CloudFlare缓存规则带来的好处就是可以大大的缓解服务器压力,将几乎所有的静态资源都缓存在CloudFlare节点IP上,全球各地的访客都可以就近请求CloudFlare节点IP来浏览网站,由此达到网站载入速度的极致优化,再配合专属于国内的优化规则,哪怕你的服务器是境外的都可以在国内实现秒开、闪过的浏览体验。因为缓存比较全面,所以就算是有CC攻击都可以就基本无视了,让他打就是了,都打在缓存上而已,加上CloudFlare安全防护加持,甚至DDoS 攻击都可以无视了,让你的Typecho站点真正成为一个打不死的小强。注:因内容违法造成域名被墙的,谁也没办法,自求多福了。二 配置教程1 准备工作好了,不废话了,我们开始今天的分享吧,首先要做的就是将你的Typecho站点采用DNS方式接入CloudFlare,当然也可以CNAME方式接入,不受限于接入CloudFlare的方式,但从效能上来说DNS接入CloudFlare是最好的。2 配置规则这里为了素材的方便,V+变量就以Typecho博客:https://www.vvars.com 为例了,大家自己用的时候记得替换为自己的域名即可,后面就不再做提示了。为了方便大家引用规则,每张规则截图后多会附上规则表达式代码,大家利用CloudFlare创建规则处提供的【编辑表达式】复制粘贴直接使用就是了。一共是三条缓存规则,缺一不可,并且三条规则是要严格按照顺序排列生效才可以,三条规则主要实现的是:1)不缓存指定的目录(如后台、搜索查询等等)。2)登录状态以及发表过评论的不缓存。3)只要不是登录状态或者发表过评论的请求一律缓存。1)第一条规则(可以起名“不缓存”)具体规则配置如下图所示:表达式为:(starts_with(http.request.full_uri, "https://www.vvars.com/admin/")) or (starts_with(http.request.full_uri, "https://www.vvars.com/search/"))符合上述条件的一律绕过缓存回源请求,所以如下图配置:保存即可。2)第二条规则(可以起名为“登录评论不缓存”)具体规则配置如下图所示:表达式为:(starts_with(http.request.full_uri, "https://www.vvars.com/") and http.cookie contains "__typecho_authCode" and http.cookie contains "__typecho_uid") or (starts_with(http.request.full_uri, "https://www.vvars.com/") and http.cookie contains "__typecho_remember_")符合上述条件的一律绕过缓存回源请求,所以如下图配置:保存即可。这条规则其实就是通过当前Typecho站点的cookie来判断是登录状态还是发表过评论状态,一般来说这都是Typecho站点的标准,所以适用大多数的Typecho主题,如果你的Typecho主题是多用户模式的话,那可能就得根据需要来修改这条规则了,一般通过浏览器“开发者工具”调试就能获得具体的cookie,只能大家自己搞定了。也可以评论去留言咨询明月哦!3)第三条规则(可以起名为“缓存所有”)具体规则配置如下图所示:表达式为:(starts_with(http.request.full_uri, "https://www.vvars.com/") and not http.cookie contains "__typecho_authCode" and not http.cookie contains "__typecho_uid" and not http.cookie contains "__typecho_remember_") or (starts_with(http.request.full_uri, "https://www.vvars.com/usr/uploads"))这个规则跟第二条规则正好相反,凡不是登录状态或者留过言状态的请求一律缓存当前所有资源,评论留言要排除的原因就是否则会造成评论信息混乱,比如:A客户的留言信息被B客户看到并能直接发表评论。因为第三条规则是缓存所有,所以下面的缓存配置就要配置一下了,不能是【绕过缓存了】,具体配置如下图所示:CloudFlare里这个边缘TTL缓存指的就是CloudFlare节点IP上的缓存,所以这里配置的意思就是在节点IP上保留缓存资源7天的时间,除非你发布的文章需要经常修改变更,否则这个边缘TTL时间越长缓存命中率就越高,自然访客的访问速度就会一直保持非常快的体验。这个浏览器TTL指的是在客户浏览器里保留缓存多久,一般这里的时间是一定要短于边缘TTL时间的,因为边缘TTL缓存我们可以通过CloudFlare后台清除缓存来情理掉,而这个浏览器TTL缓存是在客户电脑上的,我们是不可能清理的,所以最好的办法就是让其缓存时间短一些,超过这个时间就到边缘TTL上请求更新一下,最科学。剩下的就是有关缓存的细节配置了,就不一一介绍了,大家参照上图勾选就是了,最后保存规则即可。3 效果查看三条规则保存后,最后一步还要确认一下规则顺序如上图所示,否则规则生效就会出错哦,按照这个顺序就可以让CloudFlare来智能自动的缓存网站资源了,随着访客数量的增加,CloudFlare后台【分析日志】——【流量】里大家就可以看到缓存命中情况了,如下图明月的:这个缓存命中率已经80%以上了,这还是V+变量今天调整了博客首页,多次更新了缓存,否则这个命中率可以高达90%以上,这还多亏了Typecho系统的简洁和V+变量所用的Joe主题静态化做的好,现在V+变量的这个Typecho站在CloudFlare缓存的加持下几乎是0回源请求,前端的访问速度也是达到了极致,只能说CloudFlare威武!哈哈!