搜索到
95
篇与
的结果
-
 Debian13-安装最新版qbittorrent-Nox,干掉默认密码并重置密码 0 前言最近购买的大盘鸡装的系统是Debian13,用之前的一键脚本报错 新手PT刷流一键安装与使用教程 ,提示脚本不支持Debian13。1 安装与配置1.1新源可以在此查询构建好的包1) 备份并编辑源列表sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak sudo nano /etc/apt/sources.list添加以下内容 这里添加了trixie 源deb http://deb.debian.org/debian trixie main contrib non-free deb-src http://deb.debian.org/debian trixie main contrib non-free2) 更新包索引sudo apt update1.2 安装qbittorrent-nox直接使用以下命令安装qbittorrent-nox:sudo apt install qbittorrent-nox -y1.3设置开机自启动1)创建qbittorrent-nox.service文件:nano /etc/systemd/system/qbittorrent-nox.service2)把以下内容复制进去:[Unit] Description=qBittorrent Command Line Client After=network.target [Service] Type=simple User=root Group=root UMask=007 WorkingDirectory=/root/.config/qBittorrent ExecStart=/usr/bin/qbittorrent-nox --webui-port=8080 Restart=on-failure [Install] WantedBy=multi-user.target3)按Ctrl+O保存,再按Ctrl+x退出。4)修改qbittorrent-nox.service文件后重新载入:sudo systemctl daemon-reload5)设置开机启动:sudo systemctl enable qbittorrent-nox6)启动qbittorrent-nox:sudo systemctl start qbittorrent-nox7)停止qbittorrent-nox:sudo systemctl stop qbittorrent-nox8)安装完成打开浏览器,输入http//ip地址:8080,就可以打开qbittorrent-nox的webui了1.4 密码问题1)关于默认密码新版本qbittorrent不再使用默认密码,而是随机生成密码,应该会输出在日志里。2)查看日志journalctl -fu qbittorrent-nox可以看到账号密码3)修改密码(1)手动修改配置文件如果没有正确输出,可以手动修改配置文件vim /etc/systemd/system/qbittorrent-nox.service(2)添加WorkingDirectory[Unit] Description=qBittorrent Command Line Client After=network.target [Service] Type=simple User=root Group=root UMask=007 WorkingDirectory=/root/.config/qBittorrent ExecStart=/usr/bin/qbittorrent-nox --webui-port=8080 Restart=on-failure [Install] WantedBy=multi-user.target(3)编辑配置文件vim /root/.config/qBittorrent/qBittorrent.conf(4)添加以下内容[Preferences] WebUI\Password_PBKDF2="@ByteArray(ARQ77eY1NUZaQsuDHbIMCA==:0WMRkYTUWVT9wVvdDtHAjU9b3b7uB8NR1Gur2hmQCvCDpm39Q+PsJRJPaCU51dEiz+dTzh8qbPsL8WkFljQYFQ==)"4)重载密码# 停止服务 systemctl stop qbittorrent-nox # 重新加载 systemd 配置 systemctl daemon-reload # 启动服务 systemctl start qbittorrent-nox此时能用账号密码admin adminadmin登录,记得登录后修改默认账号密码。
Debian13-安装最新版qbittorrent-Nox,干掉默认密码并重置密码 0 前言最近购买的大盘鸡装的系统是Debian13,用之前的一键脚本报错 新手PT刷流一键安装与使用教程 ,提示脚本不支持Debian13。1 安装与配置1.1新源可以在此查询构建好的包1) 备份并编辑源列表sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak sudo nano /etc/apt/sources.list添加以下内容 这里添加了trixie 源deb http://deb.debian.org/debian trixie main contrib non-free deb-src http://deb.debian.org/debian trixie main contrib non-free2) 更新包索引sudo apt update1.2 安装qbittorrent-nox直接使用以下命令安装qbittorrent-nox:sudo apt install qbittorrent-nox -y1.3设置开机自启动1)创建qbittorrent-nox.service文件:nano /etc/systemd/system/qbittorrent-nox.service2)把以下内容复制进去:[Unit] Description=qBittorrent Command Line Client After=network.target [Service] Type=simple User=root Group=root UMask=007 WorkingDirectory=/root/.config/qBittorrent ExecStart=/usr/bin/qbittorrent-nox --webui-port=8080 Restart=on-failure [Install] WantedBy=multi-user.target3)按Ctrl+O保存,再按Ctrl+x退出。4)修改qbittorrent-nox.service文件后重新载入:sudo systemctl daemon-reload5)设置开机启动:sudo systemctl enable qbittorrent-nox6)启动qbittorrent-nox:sudo systemctl start qbittorrent-nox7)停止qbittorrent-nox:sudo systemctl stop qbittorrent-nox8)安装完成打开浏览器,输入http//ip地址:8080,就可以打开qbittorrent-nox的webui了1.4 密码问题1)关于默认密码新版本qbittorrent不再使用默认密码,而是随机生成密码,应该会输出在日志里。2)查看日志journalctl -fu qbittorrent-nox可以看到账号密码3)修改密码(1)手动修改配置文件如果没有正确输出,可以手动修改配置文件vim /etc/systemd/system/qbittorrent-nox.service(2)添加WorkingDirectory[Unit] Description=qBittorrent Command Line Client After=network.target [Service] Type=simple User=root Group=root UMask=007 WorkingDirectory=/root/.config/qBittorrent ExecStart=/usr/bin/qbittorrent-nox --webui-port=8080 Restart=on-failure [Install] WantedBy=multi-user.target(3)编辑配置文件vim /root/.config/qBittorrent/qBittorrent.conf(4)添加以下内容[Preferences] WebUI\Password_PBKDF2="@ByteArray(ARQ77eY1NUZaQsuDHbIMCA==:0WMRkYTUWVT9wVvdDtHAjU9b3b7uB8NR1Gur2hmQCvCDpm39Q+PsJRJPaCU51dEiz+dTzh8qbPsL8WkFljQYFQ==)"4)重载密码# 停止服务 systemctl stop qbittorrent-nox # 重新加载 systemd 配置 systemctl daemon-reload # 启动服务 systemctl start qbittorrent-nox此时能用账号密码admin adminadmin登录,记得登录后修改默认账号密码。 -
将免费进行到底——为 Alice IPv6 免费鸡添加官方 IPv4 出口 | tun2socks 的 sing-box 实现 一 前言众所周知,Alice IPv6 免费鸡只有 IPv6 并没有 IPv4 出口,要用爽的话还得添加 IPv4 出口但总不能总依靠 CF 大善人的 warp 吧?家人们总还是要吃点好的(但 Alice 大善人提供了5个 Socks5 出口,我们可以利用它,把 socks5 代理作为本机的 IPv4 出口!不过本次教程不会教大家简单的添加一个 socks5 出站,而是教大家添加tun网卡,实现 tun to socks!二 安装教程闲言少叙,正片开始!1. 安装并配置 sing-boxsing-box 提供了一键脚本可以一键安装:curl -fsSL https://sing-box.app/install.sh | sh验证是否正确安装:sing-box version有输出就算安装啦~ sing-box version 1.11.14 Environment: go1.24.4 linux/amd64 Tags: with_gvisor,with_quic,with_dhcp,with_wireguard,with_utls,with_reality_server,with_acme,with_clash_api,with_ech Revision: 9b8ab3e61e5b3a199fce5575bc6a04373f222d22 CGO: disabled或者可以使用 sing-box 官方提供的其他安装方法2. 配置 sing-box (tun2socks)编辑 sing-box 配置文件在 /etc/sing-box/config.json 里添加以下配置: { "log": { "disabled": true, //关闭日志(隐私考虑) "level": "info" }, "inbounds": [ { // 添加 tun 入站 "type": "tun", "tag": "tun-in", "address": ["172.16.0.1/30", "fdfe:dcba:9876::1/126"], "route_exclude_address": "::/0", //排除所有 IPv6 路由(非常重要!) "mtu": 1492, "auto_route": true, "strict_route": false, //严格模式关掉,以便正常流量通过(也很重要!) "stack": "mixed", } ], "outbounds": [ { //添加 socks5 出站(默认使用第一个出站) "type": "socks", "tag": "socks-out", "server": "2a14:67c0:116::1", "server_port": 20000, //更改端口变更出站节点 "version": "5", "username": "alice", "password": "alicefofo123..OVO", "bind_interface": "eth0" //绑定接口防止回环 }, { "type": "direct", "tag": "direct-out", "bind_interface": "eth0" //绑定接口防止回环 } ], "route": { "auto_detect_interface": true, //自动侦测接口防止回环 "rules": [ { //添加 IPv6 规则,增加鲁棒性 "ip_version": 6, "outbound": "direct-out" } ] } }我这里只提供了一个比较基础的模版,有实力的话可以自己写更多~重启 sing-box:systemctl restart sing-box这里可以验证一下是否真的成功:curl api.ipify.org返回:112.120.48.210有输出 IPv4 就算成功啦~如果发现进不了SSH,一定就是没有配置排除路由(route_exclude_address)导致的!这样的话也只能进入 Alice 的 VNC 后台去把 sing-box 关掉了 :(命令:systemctl stop sing-box如果一切没问题的话,那就可以设置开机自启动:systemctl enable sing-box这样就大功告成啦~3. 享受~至此,你已经通过 sing-box 实现 tun2socks !然后就可以随便想访问 IPv6 就访问 IPv6,想访问 IPv4 就访问 IPv4 啦!三、后言实际上可以使用现成的 tun2socks ,但为什么不用它?因为配置起来太复杂,要手动添加tun虚拟网卡,还要手动配置路由,就很麻烦,最后发现果然还是 sing-box 这种一体式的管理比较方便,也适合我们这种懒人
-
网络视频格式究极之战——选择webm还是mp4,以及mp4转换为webm的方式 WebM 和 MP4 都是流行的数字视频格式。先说结论,如果选择兼容性,MP4 是两者中更好的选择,因为它提供了跨各种平台和设备的更多兼容性,它是一种使用更广泛的格式,大多数视频播放器都支持它。如果你想创建一个针对网络使用优化的视频并且不介意牺牲一些兼容性,那么 WebM 是更好的选择。一、MP4和webm特点与差异1.1 MP4MP4,也称为 MPEG-4 Part 14,是一种遵循 ISO/IEC 标准的容器格式,用于存储音频和视频。此外,与 WebM 不同,MP4 还可以存储其他重要数据,如图像和字幕。这种格式的所有文件都以 .mp4 扩展名结尾,需要注意的是 MP4 不是一种开源文件格式。1.2 webmWebM 是谷歌于 2010 年推出的一种媒体文件格式。它是开源的并且 100% 免版税。WebM 格式的文件结构基于 Matroska 容器,这使其能够支持惊人的视频质量。从本质上讲,WebM 是专门为 Web 设计的,是 HTML5 中支持的较为突出的视频标准之一。1.1 两者的主要差别以下是 WebM 和 MP4 之间的一些主要区别,您在继续阅读之前应该记住这些区别。规格WebMMP4开发者谷歌国际标准化组织文件扩展名.webm.mp4支持的视频编解码器VP8 或 VP9H.265/HEVC、H.264、AVC支持的浏览器和平台歌剧、Chrome、火狐、资源管理器所有主要平台、设备、平台和媒体播放器支持串流专为互联网流媒体和共享而开发最适合上传视频并进行共享支持的设备手持和移动设备的支持不是很好支持所有流行的设备和浏览器、操作系统等二、桌面环境下MP4转webm的软件在 Windows 和 Mac 上将 MP4 转换为 WebM,可以选择如下软件:2.1 Blu-ray Master Video Converter UltimateVideo Converter Ultimate 是一款适用于 Windows 和 Mac 的用户友好型转换器。使用 Video Converter Ultimate,您无需安装多个应用程序即可转换各种视频格式。它配备了多种解决方案,包括 MP4、AVI、MKV、MPG、WebM 等转换器。此桌面程序支持更多音频和视频编解码器,允许您将编码器更改为 H.264、MPEG-4、H.265、AAC 等。此外,它是配置更多设置(例如分辨率、比特率、帧速率和视频质量)的好地方。单击下载按钮,亲自尝试最好的 MP4 到 WebM 转换器。1)下载并安装 Blu-ray Master Video Converter Ultimate。Windows免费下载macOS免费下载2)选择要转换的源文件启动软件并点击 添加文件 按钮从您的文件夹导入 MP4 文件。如需多次转换,请重复点击该按钮或从左上角选择“添加文件夹”选项。3)选择输出格式打开 输出格式 列表,然后选择 WebM 从“视频”选项卡中选择现有分辨率或单击“自定义配置文件”按钮创建新分辨率。从对话框中配置输出设置,完成后,单击“新建”按钮。4)保存输出文件在将 MP4 更改为 WebM 之前,请从“保存到”菜单中选择指定的文件夹。然后,单击 全部转换 按钮来处理转换。2.2 VLC Media PlayerVLC Media Player也是 MP4 转 WebM 软件,媒体播放器不仅用于视频或音频播放,还提供免费转换器。一些用户称其为隐藏的宝石,因为并非所有媒体播放器都能够转换。VLC 易于使用,但对于一些初学者来说,其高级设置可能是一个具有挑战性的工具。不过,以下是使用 VLC 媒体播放器将 MP4 转换为 WebM 的简单步骤。1) 安装vlc播放器如果您的设备上仍未安装 VLC,您可以从 VLC 官方网站获取。安装并运行该应用程序。转到 媒体 菜单并选择 转换/保存 选项。点击 添加 从“打开媒体”窗口中单击按钮并导入 MP4 文件。2) 转换webm旁边是 转变 页面,打开 轮廓 下拉菜单并选择 WebM 格式。进入目标菜单并单击浏览按钮选择位置文件夹。单击开始按钮开始将 MP4 转换为 WebM。2.3 HandbrakeHandBrake 是一款视频转码器,可以将 .mp4 转换为 .webm。虽然最初是为 DVD 翻录而设计的,但 HandBrake 已升级为适用于多种支持输入视频的多功能工具。它提供高质量的结果,但许多用户不熟悉它的导航。如果您想使用此解决方案,请按照以下演示操作。1)安装 HandBrake在计算机上下载并安装 HandBrake。在主菜单中,点击 开源 按钮并上传文件。或者,您可以将文件拖放到界面上。继续在 HandBrake 上将 MP4 转换为 WebM 的下一部分。2)选择输出格式为webm来自 输出会话 菜单,选择 WebM 格式。如果需要,您可以从 Inspector 部分编辑输出,例如 FPS、质量、比特率等。3)转换步骤3.编辑完成后,选择要存储转换文件的文件夹,然后单击 开始编码 按钮将 MP4 转换为 WebM VP8。三、在线MP4转webm网站3.1 Blu-ray Master这是 Blu-ray Master 的 Video Converter Ultimate 官方在线版本。 免费在线视频转换器 包含一个初学者友好的用户界面,仅包含转换所需的功能。但即使它是一个免费的在线工具,它也能保证与软件相同的高质量输出,为您提供高级设置以更改输出编码器、分辨率等。使用免费在线视频转换器在任何流行的浏览器上无限制地在线将 MP4 转换为 WebM。Blu-ray Master官网在线转换地址1) 访问官网访问官方网站并点击 启动免费转换器 按钮。它会要求您安装启动器以启用在线工具。完成后,再次单击相同的按钮并上传文件。2) 选择输出格式从页面底部选择输出格式。然后,继续 自定义配置文件 单击齿轮图标。3)配置输出参数并转换出现对话框时,更改分辨率、编解码器、帧速率等。单击 好的 按钮,然后单击 转换 按钮。这就是如何使用免费在线视频转换器将 MP4 转换为 WebM。这是软件版本的反映。它易于导航,无需付费,可立即提供相同的高质量结果。3.2 ZamzarZamzar 以其干净、不错的转换质量而闻名。它支持数百种文件转换,包括视频、音频和文档。确实,对于寻找最佳 MP4 到 WebM 转换器的用户来说,在线转换器是一个巨大的帮助。1) 访问官网Zamzar官网在线转换地址2) 选择要转换的文件点击 选择文件 按钮并从本地文件夹中选择要转换的文件。您还可以从下拉列表中选择其他来源,例如 Google Drive、OneDrive 和 URL。3) 选择输出格式从下一步中选择输出格式。从 视频 部分并点击 WebM。最后,点击 立即转换 按钮并等待转换完成。从 MP4 到 WebM 转换器下载文件。四、常见问题4.1 WebM 质量高吗?是的,WebM 是一种高质量的视频格式。它是一种开源、免版税的格式,通常用于在线视频流,例如 YouTube 和 Vimeo。WebM 即使在技术规格非常低的设备上也能提供高质量的播放,使其成为在线流媒体视频的理想选择。4.2 YouTube 使用 MP4 还是 WebM?YouTube 接受 MP4 和 WebM 视频格式。但 MP4 是 Youtube 视频推荐的视频格式。4.3 WebM 还是 MP4 质量更好?这取决于两种格式的使用情况。MP4 是普遍支持的,因此在网站上上传文件时,您可以选择它。但是,WebM 提供了出色的质量,而不会使文件大小过大,如果平台有限制,WebM 会更好。4.4 WebM 是有损的还是无损的?WebM 是一种有损压缩格式。
-
中国移动H60G光猫修改超级管理员密码 中国移动的光猫H60G是一款支持光纤接入的调制解调器(光猫),通常用于家庭宽带网络的接入和路由功能。本文介绍了如何修改移动光猫H60G修改光猫超级管理员密码。一、基础信息型号: H60G(中国移动定制版)接口类型: 通常包含光纤接口(PON)、千兆LAN口、电话接口(VoIP)、USB接口等。功能: 支持光纤转WiFi/有线网络、IPTV、VoIP电话等。默认管理地址: 192.168.1.1 或 192.168.0.1默认登录账号密码:普通用户:user / 密码见设备背面标签。超级管理员(需谨慎操作):CMCCAdmin / 密码可能为 aDm8H%MdA 或随机生成(需联系移动客服获取)。二、修改光猫超级管理员密码1、先登录光猫后台用普通用户先进去(账号密码在光猫背面用户名一般为:user),然后点网络--远程管理--Password 把密码记录好等会用到另外还需要记住宽带账号和密码(如果不需要改桥接 就不用记)不知道密码的可以发送短信CZKDMM到10086重置密码2、恢复出厂设置拔掉光纤,拿牙签捅光猫后面的reset孔,不要松掉,看光猫表面,绿灯全亮一次(不能松),等待几秒后绿灯全亮两次后松开(此款光猫就是这样,一共亮三次后才算完全恢复出厂设置,一次是重置而已)。电脑用网线直连光猫LAN口(因为此款光猫无wifi)。3、使用移动默认超级用户登录账号:CMCCAdmin密码:aDm8H%MdA建议用复制,区分大小写。登录后别急着操作,点击--安全--telnet配置--勾选启用WAN侧telnet--勾选启用LAN侧telnet--记录下用户名、密码(也可自定义,我这里用默认的),点击确定。如下图:4、操作光猫下发数据右上角退出登录--插上光纤--选择设备注册--输入第一步记录下的password值--下发数据,(因为我已经注册,截不到图,哈哈哈)5.Telnet登录光猫等待下发数据完成,管理员密码自然变成随机了,用默认超级用户肯定进不去,这时候我们走telnet操作。开始--运行(没有就Windows键+R)--cmd--弹出命令行窗口--输入:telnet 192.168.1.1(回车)(出现telnet不是内部或外部命令的,自己手机百度下怎么开启telnet客户端,小白操作经常问这个问题)输入telnet用户名(3记录的)(回车)--输入密码(第四步记录的,输入的时候不会显示的)(回车)--标识符变成“~$”了输入:su(回车)--输入密码(这时候的密码就是移动本身超级用户的密码:aDm8H%MdA,输入时还是不显示,特别注意大小写,注意大小写,注意大小写!!!说三遍,因为不会显示,很多输入不成功的)(回车)--标识符变成“/#”--这时候就提权成功了6.修改超级管理员密码修改管理员超级账号的密码 aDm8H%MdA (可自定义)sidbg 1 DB set DevAuthInfo 0 Pass aDm8H%MdA如果下次登录的时候提示密码错误 可能密码被远程重置了 可以再次进入telnel重置密码就行
-
通过1panel使用docker部署bitwarden并配置mysql数据库和CDN加速以及自动化备份教程 在此之前你需要准备:聪明的脑子,灵活的手 ,友善的嘴巴,认真的耳朵。废话不多说我们开始吧!一、环境准备与1Panel安装1.服务要求推荐系统:Ubuntu/debian(务必使用最新的系统,不建议使用Centos)硬件配置:1核CPU以上、2GB内存、20GB存储(支持轻量级MySQL运行)域名:需要自己的独立域名,可选是否备案(用于HTTPS证书申请和CDN加速)2.开始搭建首先通过你能想象到的一切方法打开你购买的服务器ssh终端连接然后输入以下命令Ubtnuncurl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sudo bash quick_start.shDebiancurl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && bash quick_start.sh一路回车最后记录下ssh终端打印的1panel信息(外网/内网连接地址,用户名和密码),浏览器打开服务器的1panel网页管理地址登录到1panel管理面板后恭喜你已经完成了第一小步子 xhj016二.部署bitwarden前的准备1.登入1panel后找到侧边栏选择应用商店并打开选择安装如下软件1)mysql(数据库,最新版本即可)2)OpenResty(web平台,用于反向代理bitwarden到外网)这两个软件直接点击搜索然后一键安装即可2.创建一个mysql数据库点开1panel侧边栏的数据库按钮跳转的数据库页面后请按照如下配置创建数据库: 数据库名称(自定义) 数据库用户名(自定义) 数据库密码(自定义,建议使用复杂密码) 权限(所有人%)确定配置后点击确认即可3.创建一个网站用于反向代理bitwarden服务点开1panel侧边栏的网站按钮>网站选项跳转网站管理页面后请按照如下配置创建反向代理网站网站类型(反向代理) 分组(默认) 主域名(你为bitwarden准备的专用域名) 其他域名(默认不写) 监听IPV6(可选可不选) 代号(同网站目录地址,默认即可) 代理地址(填写bitwarden服务地址端口,本篇教程为http://127.0.0.1:8080)三.开始部署bitwarden1.打开1panel的应用商店搜索Bitwarden2.点击安装(请按照如下要求配置)名称(随意,推荐使用Bitwarden,BitwardenServer,Vaultwarden,VaultwardenServer等名字) 版本(默认即可,后续会通过自定义 compose修改安装版本) 端口(这里使用8080) 高级设置(这里要开启) 容器名字(与第一个配置“名称”一样即可) 端口外部访问(这里不要开) CPU限制(默认即可) 内存限制(默认即可) 编辑 compose文件(这里要开启) 拉取镜像(开启)3.自定义 compose配置networks: 1panel-network: external: true # 定义服务列表 services: # 服务名称:vaultwarden(Bitwarden 密码管理器的 Rust 实现) vaultwarden: # 指定容器名称(使用环境变量 CONTAINER_NAME 的值) container_name: ${CONTAINER_NAME} # 部署配置(通常用于 Docker Swarm,但单机模式也可识别) deploy: # 资源限制配置 resources: limits: # 限制 CPU 核数(使用环境变量 CPUS 的值) cpus: ${CPUS} # 限制内存使用量(使用环境变量 MEMORY_LIMIT 的值) memory: ${MEMORY_LIMIT} # 环境变量配置 environment: # 启用管理员令牌 ADMIN_TOKEN: true # MySQL 数据库连接字符串(格式:mysql://用户名:密码@主机:端口/数据库名) # 这里按照格式填写之前创建的数据库连接信息 DATABASE_URL: "mysql://vaultwarden:passwo@1Panel-mysql-OeCW:3306/vaultwarden" # 使用官方最新版镜像 image: vaultwarden/server:latest # 容器标签(用于元数据管理) labels: createdBy: Apps # 标识创建者 # 连接到的网络 networks: - 1panel-network # 使用预定义的 1panel-network # 端口映射(格式:主机IP:主机端口:容器端口) ports: - ${HOST_IP}:${PANEL_APP_PORT_HTTP}:80 # 将主机端口映射到容器 80 端口 # 重启策略:始终自动重启 restart: always # 数据卷映射 volumes: # 将宿主机 /opt/vaultwarden 目录挂载到容器 /data 目录 - /opt/vaultwarden:/data四.启动Bitward并配置自动备份以上步骤全完成后就可以尝试启动Bitwarden服务了,这时候把第二部分第三步创建的网站的域名解析到服务器上,后打开域名应该就可以访问vaultwarden了(如果不行请检查是否配置正确)这时候回到1panel管理面板页面开始配置自动备份
-
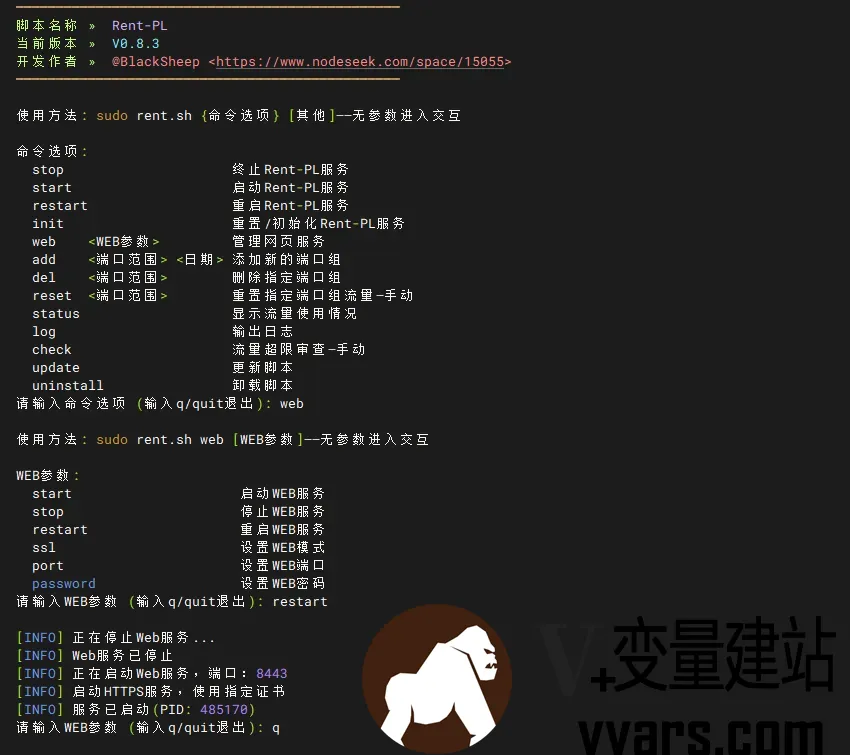
来自Ns的端口流量限制脚本——Rent-PL ~出租流量的另一种选择 1 前言原帖来自Nodeseek的BlackSheep大佬。Rent-PL是一个端口流量限制脚本,对用户指定的端口组进行流量的统计、限制与周期性重置1.1功能特点基于iptables及cron实现了端口流量统计、流量超限拦截和流量定期重置三大核心功能高可用性,支持TCP+UDP、IPv4+IPv6低破坏性,不会改动已有的iptables规则及cron任务高灵活性,支持添加多组端口/端口范围/两者的组合简易WEB服务,查询流量无需登录机器统计指定sports+出站及指定dports+入站的流量——用于转发、代理类用途时,可视为单向流量1.2项目地址GitHub:https://github.com/BlackSheep-cry/Rent-PLRaw链接:https://raw.githubusercontent.com/BlackSheep-cry/Rent-PL/main/rent.sh2 快速使用以下以Debian/Ubuntu系统为示例2.1安装依赖sudo apt update && sudo apt upgrade sudo apt install iptables bc python3 wget nano openssl其他部分发行版可能还需手动安装cron (cronie/dcron)2.2下载并启动脚本wget -q https://raw.githubusercontent.com/BlackSheep-cry/Rent-PL/main/rent.sh -O /usr/local/bin/rent.sh && chmod +x /usr/local/bin/rent.sh && rent.sh set2.3端口配置模板配置格式:单端口/端口范围/两者的自由组合 月度流量限制(GiB) 重置日期(1-28日) 例如 : 6020-6030 100.00 1 443,80 1.5 15 5201,5202-5205 1 20 7020-7030,7090-7095,7096-8000 10 12PS: 组合端口时请用英文逗号隔开,端口 流量 日期三个参数中间用空格隔开2.4交互模式sudo rent.sh2.5命令行模式sudo rent.sh 命令选项 其他3 Nginx配置WEB服务中如果选择模式1则需要自行在本地配置Nginx/Caddy等作为前置,楼主在这里为不熟悉的朋友提供一个简单的Nginx配置教程3.1安装Nginxapt install nginx3.2修改配置文件nano /etc/nginx/sites-available/rent.conf3.3配置模板(默认443端口,http重写至https)server_tokens off; client_max_body_size 1m; server { listen 443 ssl http2; # 标准HTTPS端口 server_name your.domain; # 修改为您的域名 ssl_certificate /etc/nginx/ssl/rent.crt; # 修改为您的证书路径 ssl_certificate_key /etc/nginx/ssl/rent.key; # 修改为您的私钥路径 ssl_protocols TLSv1.2 TLSv1.3; ssl_prefer_server_ciphers on; ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384; ssl_ecdh_curve secp384r1:X25519; ssl_session_timeout 10m; ssl_session_cache shared:SSL:10m; ssl_session_tickets off; ssl_stapling on; ssl_stapling_verify on; resolver 8.8.8.8 1.1.1.1 valid=300s; resolver_timeout 5s; add_header Strict-Transport-Security "max-age=63072000; includeSubDomains; preload"; add_header X-Content-Type-Options "nosniff"; add_header X-Frame-Options "SAMEORIGIN"; add_header X-XSS-Protection "0"; add_header Content-Security-Policy "default-src 'self'; script-src 'self' 'unsafe-inline'; style-src 'self' 'unsafe-inline'; img-src 'self' data:; report-uri /csp-report;"; add_header Referrer-Policy "strict-origin-when-cross-origin"; location / { limit_except GET HEAD { deny all; } proxy_pass http://localhost:8080; # 修改为您的WEB端口 proxy_http_version 1.1; proxy_set_header Connection ""; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_buffering off; proxy_request_buffering off; proxy_connect_timeout 10s; proxy_send_timeout 15s; proxy_read_timeout 30s; } location ~* ^/(\.git|config|backup) { deny all; return 403; } } # HTTP重写至HTTPS server { listen 80; server_name your.domain; # 修改为您的域名 return 301 https://$host$request_uri; }3.4启用站点ln -s /etc/nginx/sites-available/rent.conf /etc/nginx/sites-enabled/3.5重载Nginx,配置完毕nginx -s reload3.6禁用站点rm /etc/nginx/sites-enabled/rent.conf4使用截图5注意事项1)问题反馈:主日志在/var/log/rent.log,WEB日志在/tmp/web_service.log2)如果你使用iptables进行流量转发,请将落地机和中转机端口保持一致,否则脚本无法正常统计流量3)status命令显示的月度限制发生变化是预期行为,而WEB中不会发生变化4)如果你设置的端口在动态端口范围内(可用查询),请确保端口有服务在监听,否则有小概率多统计流量PS:修改动态端口范围也可以,但不太建议:,写入新范围——不能太小,否则高并发下端口会耗尽,最后应用即可sysctl net.ipv4.ip_local_port_range sudo nano /etc/sysctl.conf net.ipv4.ip_local_port_range = xxxxx xxxxx sysctl -p
-
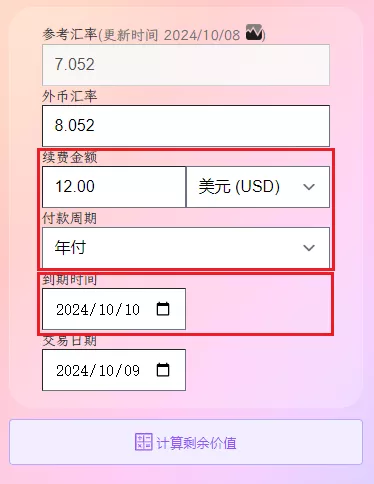
简单实用,打造属于自己的VPS 剩余价值计算器 前言很多时候,站长朋友有些吃灰的VPS不需要了,出售给其他人是个不错的选择,这个时候有个VPS剩余价值计算器是个不错的选择。对一名鸡进鸡出如家常事的 mjj 玩家来说,一枚好用的 VPS 的剩余价值计算器让你在交易中得心应手。而现有的 VPS 剩余价值计算器,使用下来每款总有那么一点点不太符合自己的口味,要么交互一点欠缺,要么功能稍有缺失,或者颜值不足...今天介绍的一款VPS剩余价值计算器来自Nodeseek的semyes大佬,其Github源码地址。🚀项目简介VPS 剩余价值计算器是一个帮助用户精确计算 VPS 产品剩余价值和剩余时间的工具。只需要输入续费金额,选择对应的付款周期、到期时间和交易日期,即可获取 VPS 剩余价值、剩余天数等信息。计算器支持多种支付货币和付款周期,外币汇率每日自动更新,支持自定义汇率计算,并提供一键分享计算结果图片功能。⚡功能特点交互合理简洁清晰的计算结果汇率每日自动更新,并且支持自定义汇率计算更准确的算法,比如大小月非直接取30天计算一键导出计算结果为图片,支持分享适应不同的屏幕,电脑和手机浏览器上体验良好首创 SVG 图片分享,速度更快、体验更佳、流量更省1. 交互合理只需要输入必要的信息,没有其它过多的要求。首先,最基本的信息,续费金额和方式,例如 12.00 美元/年。这个我认为应该是整体的,所以“续费金额”和“货币”得放一行,其次是“付款周期”,告知是“月付”还是“年付”等付款周期,三者一体。其次,到期时间。这个计算剩余多少时间,而决定 VPS 的剩余价值,因此续费金额和周期之后位置。第三,交易时间和外币汇率。两者会影响剩余价值,一般都是计算当天交易,表单默认交易日期为计算当天,外币汇率为当天的汇率。外币汇率有个细节,分固定的参考汇率和可更改的货币汇率,参考汇率是市场决定固定的,货币汇率是交易使用的实际汇率。正常情况,交易汇率直接使用参考汇率,但实际交易中,卖方或者买方可能使用自定义的汇率去计算,这样也是允许的,计算结果需要反映出这一行为。如下图所示,当参考汇率和外币汇率不相等的时候,结果会多自动新增一行,显示使用自定义的外币汇率计算的剩余价值。至于交易货币、交易金额、是否溢价等,我觉得这些都不需要,大而全反而影响使用体验。2. 简洁清晰的计算结果计算之后,需要获取的信息:续费价格及续费周期、剩余天数和过期日期、剩余价值和总价值,没有其它多余无用的信息。其中,当续费货币使用外币的时候,计算结果的总价值展示的是外币转人民币的金额,这点我是很需要的功能。3. 汇率每日自动更新,并且支持自定义汇率计算使用过的要么汇率固定,不会更新,要么有更新但只能使用更新后的汇率,不能自定义,但实际交易卖方或者买方可能使用自定义的汇率去计算,这样也是允许而且很需要的。4. 更准确的算法,比如大小月非直接取30天计算比如,2025/02/10 以 1美元/月购入服务器,下个月 2025/03/10 到期,当天转手,此 VPS 实际交易是 28 天才对,而非 30 天。目前网上的使用过的 VPS 剩余价值,几乎都是使用固定 30 天计算,对于我们这种吹毛求疵的用户,心里总感觉有一个小黑点,不完美了。5. 一键导出计算结果为图片,支持分享计算结果直接保存图片,支持复制 markdown 代码直接分享。6. 适应不同的屏幕,电脑和手机浏览器体验良好电脑和手机屏幕都有良好的用户体验。二📝Docker部署使用1 使用 docker 一键部署(推荐)docker run -d --name=jsq --rm -p=8088:80 hahabye/vps_jsq:latest2 使用 docker-compose 部署# 下载 docker-compose.yml 到本地 wget https://raw.githubusercontent.com/hahabye/vps_jsq/main/docker-compose.yml # 启动服务 docker-compose -f docker-compose.yml up -d三📝Cloudflare部署使用1下载最新的代码:https://github.com/hahabye/vps_jsq/releases/tag/latest2 解压到一个文件夹(只有一个html文件)3 部署Pagescloudflare 左边菜单 选择 Workers 和 Pages,上传文件夹,然后点击部署,完毕.整个过程不足 1 分钟完成一个理论永久在线的 vps 剩余价值计算器四📝自建WEB部署使用前两步与第三步的1、2一样,第3步直接上传到自己VPS可以访问的地址,本站https://www.vvars.com/tools/vps-jsq选择的就是这种部署方式。五 在线演示1 💻在线示例https://www.vvars.com/tools/vps-jsq2 📷运行截图VPS 剩余价值计算器
-
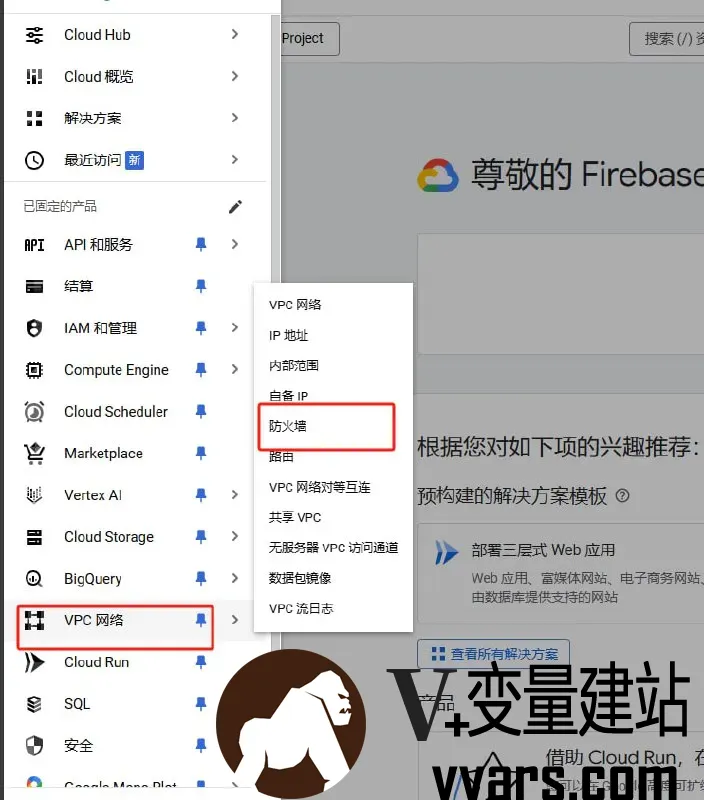
谷歌云GCP快速打开防火墙教程——利用自带的 CLI 快速打开IPV4+IPV6 防火墙 一 前言谷歌云每月200GB免费标准层互联网数据传输,足够一个小博客使用。关于谷歌云,之前本站有文章:谷歌云300赠金过期后不要丢!升级账号白嫖每月200GB流量云服务器。今天介绍如何使用GCP自带的CLI快速打开防火墙。二 利用自带的 CLI 快速打开GCP防火墙教程1.VPC网络---防火墙----删除现有的所有防火墙2.点击右上角的Cloud Shell 等待进入到系统3.将下列代码复制黏贴运行,点击回车等待代码运行并且完成curl -Ls https://raw.githubusercontent.com/networkgateways/script/main/Cloud/configure_gcp_firewall_rules.sh -o configure_gcp_firewall_rules.sh && bash configure_gcp_firewall_rules.sh4.完成
-
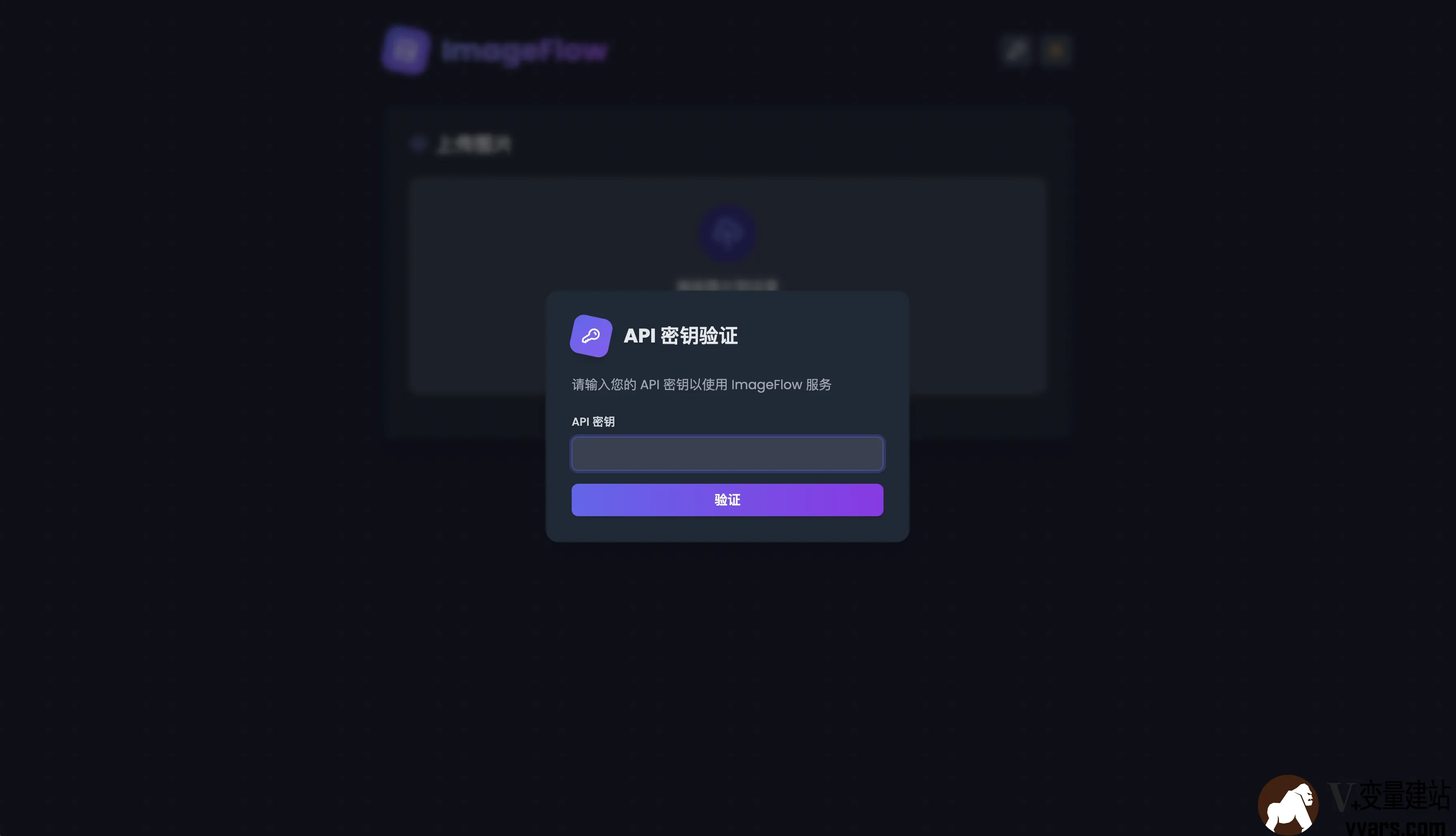
ImageFlow的安装教程:一款自动检测浏览器兼容性并提供 WebP 或 AVIF 格式图片的图床程序 一前言程序来自Nodeseek的sayyiku大佬。根据大佬介绍,其一直以来都是用的 chevereto 来作为图床管理,但是这个作者太脑瘫了。项目越改越辣鸡,经常增加一些虚头八脑的社交之类的功能,导致整个项目越来越臃肿卡顿,至于市面上其他的项目,也不想再过多尝试,大部分都是基于多用户场景的,和想要的相违背。本着既然没有,那就自己创造,还能加点自己喜欢的功能,例如 avif 和 webp 格式自动压缩,API 自适应横屏竖屏输出。于是 ImageFlow 就诞生了。仓库地址 欢迎大家给大佬点 star。关于图床,之前本站介绍过:1.用CF和BackBlaze零成本自建图床,年度最强白嫖攻略。二特点1主要特性API 密钥认证:安全的 API 密钥验证机制,保护您的图片上传功能自适应图像服务:根据设备类型(桌面端 / 移动端)自动提供横向或纵向图片现代格式支持:自动检测浏览器兼容性并提供 WebP 或 AVIF 格式图片简单的 API:通过简单的 API 调用获取随机图片用户友好的上传界面:支持拖拽上传,具有暗黑模式和实时预览功能图片管理功能:通过直观的管理界面查看、筛选和删除图片自动图像处理:上传后自动检测图像方向并转换为多种格式多存储支持:支持本地存储和 S3 兼容存储2? 技术优势安全性:API 密钥验证机制确保图片上传和管理功能的安全访问格式转换:自动将上传的图片转换为 WebP 和 AVIF 格式,减少 30-50% 的文件大小设备适配:为不同设备提供最合适的图片方向热重载:上传的图片无需重启服务即可立即可用并发处理:使用 Go 的并发特性高效处理图像转换可扩展性:模块化设计便于扩展和定制响应式设计:完美适配桌面端和移动端设备暗黑模式支持:自动适应系统主题。灵活存储:支持本地和 S3 兼容存储,通过 .env 文件轻松配置3界面预览三安装教程快速开始可以选择两种方式,都非常方便,一种是 Docker,一种是 二进制部署。1 Docker 部署1)拉取并进入仓库git clone https://github.com/Yuri-NagaSaki/ImageFlow && cd ImageFlow2)修改.envcp .env.example .env vim .env3)根据所选择的部署模式调整 参数具体 S3 的 下列参数如何获得这里就不再过多赘述了# API Keys API_KEY=your_api_key_here # 这是你的API key 用于身份验证登录 # Storage Configuration STORAGE_TYPE=local # Options: local, s3 根据部署模式选择 LOCAL_STORAGE_PATH=static/images # Local # S3 Configuration (required when STORAGE_TYPE=s3) S3_ENDPOINT= S3_REGION= S3_ACCESS_KEY= S3_SECRET_KEY= S3_BUCKET= # Custom Domain (optional) CUSTOM_DOMAIN= # 这里是S3 一般都会有的自定义域名。4)拉取镜像准备部署docker compose up -d一般默认监听8686端口,如有必要,自行修改。2 本地部署1)安装依赖1)安装 Go (1.22+)2)安装 WebP 工具: sudo apt-get install webp (Ubuntu/Debian)3)安装 AVIF 工具: sudo apt-get install libavif-bin (Ubuntu)注意:这里的需要 avif 1.0 版本以上,Debian 系统默认安装的是 0.9 版本。需要自行编译安装。Ubuntu 24.04 默认即可安装最新版本2)下载二进制文件修改 env默认提供 X86 和 ARM 的,自行选择git clone https://github.com/Yuri-NagaSaki/ImageFlow && cd ImageFlow https://github.com/Yuri-NagaSaki/ImageFlow/releases/download/v1.0/imageflow-x86 chmod 777 imageflow-x86 cp .env.example .env vim .env ./imageflow-x863)创建 service[Unit] Description=ImageFlow Service After=network.target [Service] ExecStart=/path/to/imageflow WorkingDirectory=/path/to/imageflow/directory Restart=always User=youruser [Install] WantedBy=multi-user.target三 如何使用1打开 IP:8686 端口 输入你在 env 设置的 API_Key2开始上传图片注意:由于压缩在本地进行,请选择 CPU 较强的进行部署3点击右上进入管理4这里会获取到你上传和压缩后的所有图片5当然你也可以对某个图片进行删除,他会连带删除原始图片 avif 和 webp 。6访问 APIAPI 的地址是 IP:8686/api/ramdom到此全部完成!
-
LNMP一键包Mariadb主从复制碰到的坑,如果你也碰到过,教你如何解决 0 前言这几天趁着休息把几个VPS上的LNMP都升级了下,全部换成LNMP2.2,PHP和MYSQL也升级了,PHP升级为8.3,Mysql升级为MariaDB10.11,升级后发现主从同步又要重新配置了,折腾了七八个小时总算弄好了,为避免以后少走坑,记录一下出现的问题。1 主服务器连不上如果从服务器 telnet 主服务器IP 3306 连不上,大概率是主服务器的防火墙问题,Debian系统可以按如下操作:1修改/etc/iptables的v4.rule将第15行的(有的系统可能不在第15行,按代码查找)-A INPUT -p tcp -m tcp --dport 3306 -j DROP中的DROP改为ACCEPT,改后:-A INPUT -p tcp -m tcp --dport 3306 -j ACCEPT然后重启防火墙:service iptables restart2 主从数据库不同步如果主服务器已有数据,需先手动同步数据到从服务器,重新导入一次:# 在主服务器导出数据(包含日志位置信息) mysqldump -u root -p --all-databases --master-data=2 > db_dump.sql # 在从服务器导入数据 mysql -u root -p < db_dump.sql3 检查主从服务器配置,确保ID、访问权限配置好配置文件在/etc/my.cnf:主服务器配置:[mysqld] server-id = 1 log_bin = mariadb-bin.log bind-address = 0.0.0.0从服务器配置:[mysqld] server-id = 2 -- 确保与主服务器不同 relay-log = mariadb-relay-bin.log read_only = 1注意lnmp一键包在在mysqld靠后的位置也有server-id = 1,不能重复操作后分别重启:lnmp mysql restart -- 修改配置后重启服务重启后需要确认验证主库和从库的 binlog 和 server_id:SHOW VARIABLES LIKE 'log_bin'; #应为 ON SHOW VARIABLES LIKE 'server_id'; # 必须唯一且非零4 CHANGE MASTER 命令参数有误确保在从服务器上执行 CHANGE MASTER 命令时,参数完整且正确:CHANGE MASTER TO MASTER_HOST='主服务器IP', MASTER_USER='replica_user', MASTER_PASSWORD='your_password', MASTER_PORT=3306, MASTER_LOG_FILE='mariadb-bin.000001', -- 主服务器的二进制日志文件名 MASTER_LOG_POS=12345678; -- 主服务器的日志位置关键点:MASTER_LOG_FILE 和 MASTER_LOG_POS 必须与主服务器执行 SHOW MASTER STATUS 的结果完全一致。如果主服务器未启用二进制日志(log_bin),需在主配置文件中启用并重启服务。5 确保主服务器上的复制用户(如 replica_user)具有正确的权限:在主服务器执行:SHOW GRANTS FOR 'replica_user'@'从服务器IP或%';正常显示权限如下:GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replica_user'@'%';如果有问题需要重新刷新权限:GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replica_user'@'%' IDENTIFIED BY 'your_password'; FLUSH PRIVILEGES;6 清除旧的复制配置如果从服务器曾配置过主从复制,旧配置可能导致冲突。重置从服务器状态:STOP SLAVE; RESET SLAVE ALL; -- 清除所有旧的复制信息然后重新执行 CHANGE MASTER 和 START SLAVE。7 检查MariaDB错误日志如果没找到原因,可以查看从服务器的错误日志(默认路径 /usr/local/mariadb/var/mariadb.err),定位具体错误原因:tail -n 100 /usr/local/mariadb/var/mariadb.err常见日志错误:连接主服务器失败(检查防火墙、网络、端口)。认证失败(用户名或密码错误)。二进制日志文件不存在(MASTER_LOG_FILE 名称或位置错误)。